Всем привет!
Как и обещал — продолжаю делиться прогрессом.
Тестовый стенд на ноутбучном железе в целом закрывает мои потребности в части инфраструктуры, но не надежности и объема хранения. Могу описать подробнее, что и как, но в целом в основу этого поста положено то, что сделано на тесте.
Обкатал тестовый стенд и решил делать по-взрослому. Хочу собрать фидбек, пока ещё можно всё поправить без боли.
Глобально подход к развертыванию такой - сервисы, которые не живут вне ВМ, развертываем как VM.
Всё остальное разворачиваем как LXC. Portainer оставляем как песочницу чисто за удобство, но не для пользования.
Железо
Aoostar WTR Pro
- Ryzen 7 5825U
- 32 Gb DDR4-3200
- M.2 NVMe 1 Tb — под систему
- 4 × WD Blue 1 Tb — под данные
 Хранение
Хранение
M.2 NVMe (1 Tb)
Просто стандартная разбивка local / local-lvm.
Не знаю, зачем мне 100 Gb local, которые создаются по умолчанию.
Может есть советы как поступить?
HDD (4×1 Tb) → ZFS RAIDZ1 — данные и бэкапы
ZFS pool: data
Папки
data/backups → PBS datastore (локальные бэкапы)
data/shared → общие данные для нескольких LXC
data/services → данные сервисов (внутри папки по именам хостов)
Storage в Proxmox
local-lvm— VM / LXC rootfs (NVMe)backup-data- Тип: Directory
- Путь:
/data/backups
shared-data- Тип: Directory
- Путь:
/data/shared - используется для bind mount
shared-services- Тип: Directory
- Путь:
/data/services - используется для создания папок под файлы
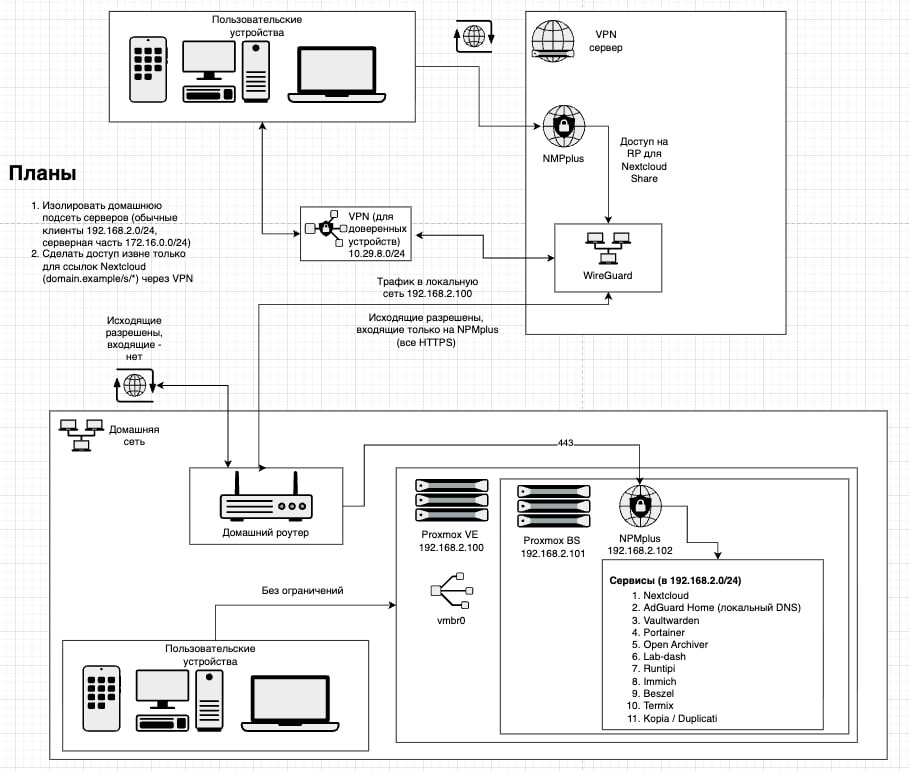
 Сеть и доступ
Сеть и доступ
- Доступ извне только через VPN
- Из-под VPN открыт только Nginx Proxy Manager (443)
- Все сервисы доступны только через NPM
- Защищено Let’s Encrypt wildcard сертификатом
- В LAN ничего не режу
- Аварийный доступ:
- на Keenetic есть ручной доступ к PVE (8006) через приложение
 Управление и мониторинг
Управление и мониторинг
- ProxMan (лучшее, на мой взгляд, мобильное приложение для iOS. Может есть другие варианты?)
- WebGUI Proxmox
- Планирую:
- уведомления (Telegram / почта)
- SMART + ZFS alerts
- уведомления о фейле бэкапов
 Бэкапы
Бэкапы
Основной механизм — Proxmox Backup Server
- PBS развёрнут в виде отдельной VM на этом же Proxmox VE
- Datastore PBS:
- HDD
- ZFS dataset
data/backups
- Бэкапятся:
- VM
- LXC
- их конфигурации
- Datastore PBS не публикуется наружу
Offsite-копии
- Для хранения вне сервера используются Kopia / Duplicati
- Они выгружают копии PBS-datastore:
- во внешнее облако WebDAV (диск)
- с клиентским шифрованием
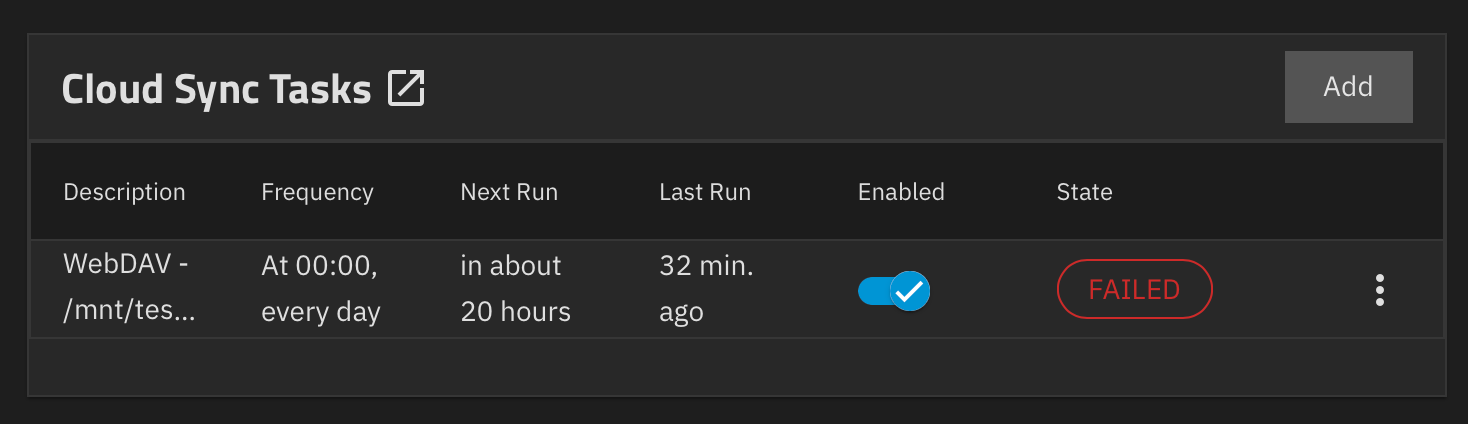
Для внимательных читателей - сейчас можно на 1 год получить бесплатно 1 Тб хранилища Сбера (надеюсь @admin не будет ругаться, Сбер мне не платит):
- Переходим по ссылке Облачное хранилище для файлов — Диск
- Авторизуемся по Сбер ID
- Введите промокод JINGLEBYTES
- профит
Схема:
VM / LXC
↓
Proxmox Backup Server
↓
ZFS (data/backups)
↓
Kopia / Duplicati
↓
WebDAV (encrypted)
Бэкап Proxmox VE
- Бэкап
/etc/pve - Хранится:
- в PBS
- уходит во внешнее облако через Kopia / Duplicati
 Shared storage между LXC
Shared storage между LXC
- Используется bind mount (через GUI не работает, только через CLI, так?)
- Общий dataset
data/shared - Проброс в несколько LXC через
mp0 - UID/GID синхронизированы между контейнерами
- SMB не используется (один хост, нет Windows-клиентов). как будто TrueNAS это сильное усложнение, но если хочется делать бэкапы Mac наверное придется и его развернуть или есть какая-то шара попроще)
Сценарии отказов (закладываю заранее)
Рассматриваю следующие ситуации:
- Отказ NVMe (M.2)
Proxmox VE иlocal-lvmнедоступны, данные сервисов остаются на HDD.
План: чистая установка PVE → восстановление конфигурации → подключение данных. - Отказ одного HDD в RAIDZ1
Пул остаётся доступен, замена диска и resilver. - Полный отказ сервера
Восстановление на новом железе из PBS + offsite-копий. - Временная недоступность облака
Локальные бэкапы в PBS продолжают выполняться, offsite догоняет позже.
Интересует, есть ли в этой схеме слабые места или неочевидные точки отказа.
Вопросы к сообществу
- Как вы бэкапите сам Proxmox VE?
Достаточно ли/etc/pveили есть смысл бэкапить что-то ещё? - PBS в виде VM на одном хосте — есть ли подводные камни?
- Локальные бэкапы VM на том же ZFS пуле — ок или плохая идея?
- Bind mount vs SMB для шаринга данных между LXC на одном Proxmox — есть ли кейсы, где SMB реально выигрывает?
- Как вы изолируете доступ?
VPN / VLAN / jump host / вообще без доступа из LAN? - Что бы вы изменили в этой схеме ДО выхода в прод, если бы собирали её сегодня?
P.S. Постарался проработать пост и написать свое видение четко, но лаконично, чтобы уважаемому читателю было комфортно.
Всех с наступющим НГ!