Рассмотрим варианты ускорения (и вообще прокачки) ZFS пула при помощи SSD дисков
В данном случае я рассматриваю на примере TrueNAS т.к. использую его в качестве NAS, но это будет применимо и для других систем на основе ZFS
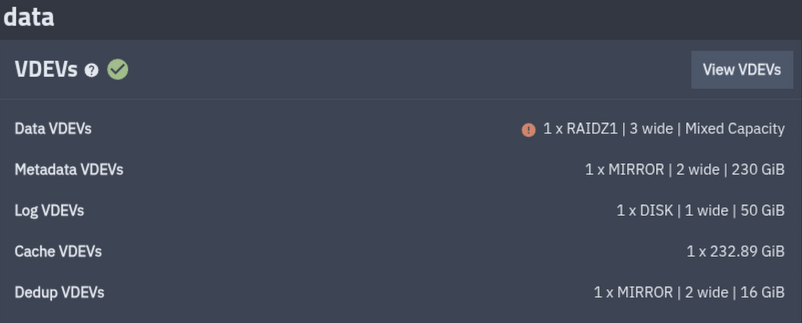
Рассмотрим типичный ZFS пул

Минимально у нас должны быть Data VDEVs, это обычные диски с данными, на основе которых строится массив.
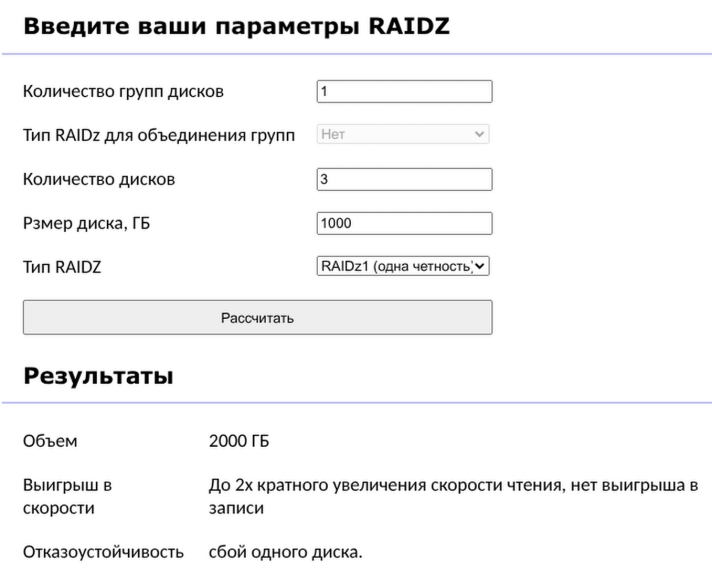
В зависимости от топологии массива у нас может присутствовать ускорение операций чтения или записи, но может и замедляться, поэтому надо разбирать топологию (вот тут есть калькулятор, можно поиграться с ним самотоятельно т.к. это выходит за рамки данного поста (но по просьбам желающих могу ниже что-то написать подробнее))
Давайте будем исходить из отказоустойчивых топологий, в которых скорость записи в лучшем случае будет соответствовать скорости записи на 1 диск, а ускорение чтения будет от N-2 до N раз. Т.е. мы понимаем, что при использовании обычных жестких дисков, особенно маленького объема (до 10 ТБ) и при интенсивном использовании нашего массива в хомлабе, мы будем упираться в скорости (что не притно, но жить можно) и в IOPS (что уже может быть очень критично), особенно когда наш NAS используется для хранения виртуалок и служебных файлов для кучи сервисов
Что такое IOPS
Input/output Operations Per Second - количество операций позиционирования головки над определенным сектором и чтение/запись этого сектора за единицу времени. При интенсивных случайных операциях ввода-вывода, например, торренты, виртуалки, несколько сервисов, хранящих данные на диске диск будет постоянно позиционироваться в разных местах и иметь задержку на выполнение этой операции
Типовые IOPS для HDD
- 5400 RPM (обычные “Green / Archive” диски) - IOPS: 60–90, задержки: ~15–17 мс
- 7200 RPM (рабочие SATA, NAS и десктопные) - IOPS: 90–150, задержки: ~12–14 мс
- 10 000 RPM SAS (HDD enterprise-класса) - IOPS: 140–200+, задержки: ~8–10 мс
Для SSD
- SATA SSD (2.5", 6 Gb/s) - IOPS: 50 000 - 100 000, задержки: ~80–120 мкс
- NVMe SSD (PCIe) - IOPS: 300 000 – 550 000, задержки: 20–40 мкс, иногда до 15 мкс
И сводная таблица
| Тип накопителя | IOPS чт./зап. | Латентность | Sequential MB/s |
|---|---|---|---|
| HDD 7200 | 100–150 | 12–14 ms | 150–220 |
| SATA SSD | 70k–100k | 80–120 µs | 550/550 |
| NVMe PCIe 3.0 | 300k–550k | 20–40 µs | 3 500 / 3 000 |
| NVMe PCIe 4.0 | 600k–1M | 10–20 µs | 7 000 / 6 000 |
| NVMe PCIe 5.0 | 1.0–1.5M | <10 µs | 14 000 / 12 000 |
| Intel Optane | 0.5M–1.1M | 6–10 µs | ~2 500 |
И тут мы можем задать вопрос: а может быть можно как-то ускорить наш массив за счет гибридной технологии?
Одно время на рынке даже были HDD диски со встроенным SSD (так называемые SSHD), для системы они выглядели как обычные диски, однако, запись была сначала на SSD, с последующим фоновым сбросом на HDD и при чтении они могли кешировать блоки HDD диска на встроенный SSD
Однако, они так и не прижились за счет низкого качества, малого объема SSD диска и примитивных микропрограмм контроллера, которые часто делали только хуже при цене, соизмеримой с отдельной парой HDD + SSD
Итак, вернемся к основной теме нашей статьи: как можно прокачать массив при помощи SSD. Для этого у нас есть несколько типов специальных дисков (special vdev):
- log (SLOG) - ускоряет синхронную запись, фактически, запись происходит на быстрый SSD с последующим фоновым сбросом данных на HDD
- cache (L2ARC) - кеширование чтений, расширяет ARC (RAM), при чтении блоков данных (может и при записи) происходит запись в этот диск, а при чтении данных ZFS читает из SSD диска, минуя HDD
- metadata (special vdev / special_small_blocks) - Хранит метаданные (список файлов) и маленькие файлы, что значительно ускоряет листинг каталогов
- dedup (DDT location) - непосредственно на скорость не влияет, однако при включении дедупликации позволяет снизить нагрузку на оперативную память, а сама дедупликация в том числе может косвенно влиять на скорость (снижая лишние чтения и запись)
Сводная таблица для пула на 6ТБ
| Тип vdev / роль | Назначение (когда полезно) | Типичный пример использования | Рекоменд. размер для пула ~6 ТБ | Рекомендуемая надёжность (надежность / при отключении) | Можно удалить? / как влияет при отказе |
|---|---|---|---|---|---|
| data (обычные vdev) | Основные данные (файлы). | HDD vdev (raidz1/2/10) — всё основное. | N/A (основной пул на HDD). | Должна быть отказоустойчивая конфигурация (mirror/raidz). При потере vdev — потеря данных. | Нельзя удалить без перестроения/перевода данных. |
| log (SLOG / separate log) | Быстрые подтверждаемые (synchronous) записи (NFS sync, databases, PBS). Ускоряет sync-writes. | NVMe/SATA SSD с высокой надежностью и энергозащитой (PLP). | Маленький: обычно 8–64 GB в зависимости от паттерна sync-транзакций (PBS рекомендует SLOG для NFS). Для 6 ТБ пула — чаще 16–64 GB достаточно. | Должен быть зеркалом (mirror) для надёжности; лучше NVMe с PLP. При потере single SLOG — синхронные записи будут писать в основную pool log area → производительность упадёт, но данные не обязательно потеряны (если не было подтверждённых транзакций на SLOG). | Можно удалить (в новых версиях OpenZFS поддерживается удаление лог-vdev), но не рекомендуется в рабочей среде без плана: удаление прекращает ускорение sync-writes; при отказе single SLOG возможна потеря ускорения и риск незавершённых транзакций. |
| cache (L2ARC) | Кеширование чтений, расширяет ARC (RAM). | SSD как L2ARC для ускорения случайных чтений/горячих блоков. | Обычно 5–10% от пула данных для общего ускорения чтений; для 6 ТБ → 300–600 GB ориентировочно. Но на практике 64–256 GB часто даёт заметный эффект при небольшом объёме горячих данных. | Кеш — неблокирующий: отказ → падение производительности чтения, данные не теряются. | Можно удалить (без потери данных). L2ARC активно перезаписывается — ускоряет чтения, но сокращает ресурс SSD при интенсивных записях. |
| metadata (special vdev / special_small_blocks) | Хранит метаданные (иноды, директории, небольшие блоки) и (при включении) DDT (dedup table). Ускоряет операции с большим количеством мелких файлов/метаданных. | SSD/ NVMe special vdev для пулов с большим количеством мелких файлов/git/контейнерных образов/много мелких random IO. | Часто 0.5–2% пула для чисто метаданных; если много мелких файлов и вы хотите поместить также DDT → 1–5% или больше. Для 6 ТБ: 64–512 GB в зависимости от плотности мелких файлов и включения dedup/DDL. | Нужно дублировать (mirror/raidz) — потеря special vdev может сделать пул нестабильным/неполнофункциональным, т.к. теряются критичные метаданные. | Нельзя удалить из пула (special vdev не удаляем). При отказе — серьёзные последствия, поэтому делать зеркалирование/избыточность обязательно. |
| dedup (DDT location) | Ускорение/экономия места при дублировании данных (очень RAM-зависимо). | Только при реальной высокой дубликации и наличии большого объёма RAM и/или DDT на fast SSD. | DDT размер зависит от объёма и уникальных блоков; не задаётся как % пула — нужно тестировать. Если планируете dedup, разместите DDT на special vdev. | Dedup сильно влияет на RAM; без резервирования отказ DDT → медленная работа. | Dedup можно отключить, но реал-влияние и удаление DDT требует переразмещения данных; не тривиально. |
Поведение при отказе / удалении — кратко
-
Cache (L2ARC): отказ безопасен — просто теряете кеш. Можно добавлять/удалять без последствий для данных.
-
Log (SLOG): без SLOG pool продолжит работу, но синхронные операции станут медленнее (они вернутся к поведению без отдельного SLOG). Если SLOG был single и умер в момент подтверждения транзакции — есть риск проблем с незавершённой транзакцией; поэтому SLOG лучше ставить в зеркало.
-
Special (metadata): отказ критичен. Special-vdev хранит метаданные и небольшие блоки; потеря может привести к повреждению метаданных и невозможности доступа. Поэтому special должен быть зеркалом/raidz и размещён на надёжных SSD. Special нельзя удалить (по вашим наблюдениям — подтверждается практикой OpenZFS).
-
Dedup (DDT): размещение DDT на fast special-vdev улучшает производительность, но в случае отказа без зеркалирования можно получить проблемы. Dedup обычно не рекомендую на пуле без большого объёма RAM.
Рассмотрим варианты комбинации дисков
Сравнение комбинаций (кратко, практические выводы)
special + log
-
Смысл: да — дополняют друг друга.
specialускоряет доступ к метаданным и мелким блокам (git, docker, множество small-file операций).logускоряет synchronous writes (NFS, PBS, databases). -
Когда полезно: если у вас и много мелких операций (иноды, метаданные) и есть синхронная нагрузка (PBS NFS, DB). Для вашей конфигурации (PBS + git/docker + NFS) — комбинация оправдана: special для responsiveness git/docker, slog для PBS/NFS.
-
Предложение: сделать mirrored NVMe для special (например 2 × 240–500 GB) + mirrored SLOG (две NVMe/SSD с PLP, 32–64 GB или больше, в зависимости от размера транзакций).
cache (L2ARC) + special
-
Смысл: частично дублируют эффект, но не одинаково. Special ускоряет метаданные и мелкие блоки на постоянной основе (они всегда хранятся на fast device), L2ARC хранит hot read-blocks (периодически перезаписываемый кеш). Если у вас много мелких случайных чтений, оба могут помочь; но special даёт более надёжный и постоянный эффект.
-
Когда не стоит: если L2ARC будет намного меньше рабочего набора горячих данных и/или он будет активно перезаписываться (media пул — много больших файлов → L2ARC быстро перезаписывается → SSD wear).
-
Предложение: для data (git/docker + fotos) — special приоритетнее. L2ARC как доп опция если у вас есть горячий набор файлов чтений, и у вас достаточно RAM (ARC) — иначе L2ARC эффективность низкая.
log + cache
- Смысл: независимы: log ускоряет записи, cache — чтения. Оба полезны в разных сценариях. Если бюджет ограничен — приоритет SLOG для PBS/NFS и special для мелких файлов; L2ARC — опционально.
Выводы
- Определенные типы дисков позволяют ускорять определенные типы операций, надо понимать характер искользования пула, например, если вы используете L2ARC на 50ГБ для чтения установочных ISO на 10ГБ + git репозиториев на 10 ГБ + фотографии на 20ГБ, то есть шанс, что большая часть чтений будет происходить с кешем, если же вы раздаете 500ГБ контента, то L2ARC будет все время переполнен и SSDшник будет просто изнашиваться без ускорения чтения т.к. каждый новый блок данных будет читаться с диска и записываться на SSD, а через мгновение новый блок, вытесняя предыдущие.
- Некоторые типы дисков критичны и требуют дублирования т.к. при потере диска есть шанс потерять весь массив
- Некоторые типы дисков после добавления нельзя удалить (по крайней мере через web интерфейс TrueNAS, GPT говорит, что в новых версиях OpenZFS можно сделать из консоли, но это не точно)
- Добавление диска в пул не приводит к переносу на него данных, это значит, что эффект сразу не увидим, для cache и slog мы увидим быстро результат, особенно для slog, а вот metadata + small blocks только новые файлы будут попадать на новые диски, старые же будут оставаться на data vdev
- Многие слышали, что ZFS любит кушать оперативную память и это правда, если оперативной памяти мало, то ZFS пул начинает сильно деградировать по скорости, добавление SSD дисков не только ускоряет работу пула, но и снижает требования к оперативной памяти.
Личной мой опыт
- Мне помогло то, что у меня сейчас 4 пула под разные задачи и они содержать разные SSD диски, подробности ниже
- Матрешка PVE → TrueNAS помогла тем, что чать SSD дисков я подключаю к хосту, там разбиваю диск на несколько разделов и уже эти разделы прокидываю в TrueNAS, что позволяет сократить количество SSD дисков, например, 1 диск на 512 режится на 2 по 256 + какой-то остаток, при замене SSD диска на новый, если там размер будет чуть меньше, то можно будет сыграть на этом пусом месте
- NVME диски, не использую, только 2.5 SATA в таком боксе (он не идеален)
- Производительность реально выросла, причем, на каки-то эпизодических операциях типа работы с git или фотками я перестал видеть разницу по сравлению с SSD
Примеры из жизни
- Скидывание 1ГБ фоток в immich раньше занимало довольно долго времени т.к. в секунду примернно сохранялось 1-2 фотки, а стали прям влетать как по маслу
- Forgejo при коммите была зареждка секунд 5 пока мелкие файлы раскидаются по дискам, при открытии репозитория в веб интерфейсе список файлов и каталогов мог подгружаться несколько секунд, сейчас это стало происходить в большинстве случаев мновенно
- PBS в ввиде виртуалки и NFS шарой для бэкапов и 600 резервными копиями список грузил до минуты, собственно с этого и 2 пункта у меня пошел процесс прокачки, после переноса PBS в LXC контейнер и добавления SSD время листинга сократилось до пары секунд максимум, часто это происходит моментально
- Создание бэкапа размером 17.86ГБ занимает 3 минуты 12 секунда от запуска до финиша
Ну и мои параметры SSD дисков для каждого типа пула
По пулам
- Бэкапы - metadata + small blocks + slog для быстрого листинга файлов и чтения файлов с метаданными + slog для быстрого создания бэкапа, cache не стал добавлять т.к. он при чтение бэкапов тоже активное и кеш будет постоянно в режиме перезаписи
- Общие данные (фотки, гит, документы, образы дисков, помойка, короче) - добавил все, кроме dedup (dedup включал на датасете с фотками где очень много дублей, типа папка разобрать, папка SD карточки, папка с разобранными фотками)
- Media (фильмы, аудиокниги, музыка) - только данные без SSD т.к. смысла в metadata нет - файлы большие, slog не то, чтобы критично, cache будет постоянно переполнен
- NVR - аналогично Media, последовательная запись с эпизодисеским чтением файлов, при этом список файлов все равно на стороне Frigate, в теории можно добавить metadata, но выделять под это 2 SSD диска (или раздела на них) не вижу смысла
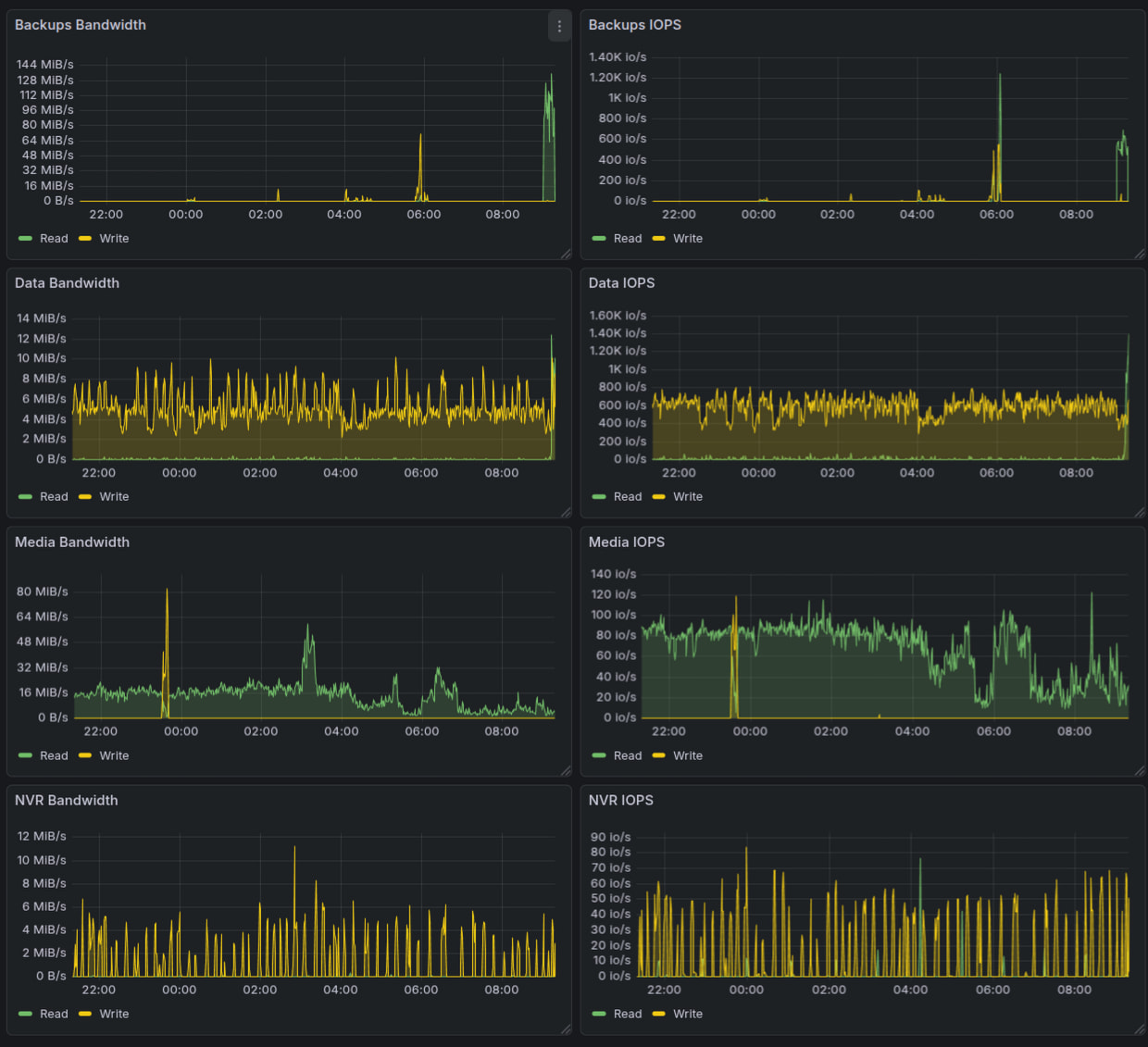
Графики по пулам, тут видно, что Media и NVR упираются в IOPS жесткого диска (порядка 80 для 5400), Data и Backups переваливают за 1000 IOPS
По типам дискв
- Data - некоторые с дублированием RAIDz, но для NVR и Media потеря данных явно не так критична, как потеря фоток
- Cache VDEV - один SSDшник, тут вообще не критично
- Metadata + small blocks - Mirror т.к. потеря SSD приведет к неработающему RAID массиву
- Slog, по хорошему тоже надо mirror, но мне жалко еще один SSD втыкать, у меня и так 4 штуки воткнуто, потеря SSD приведет максимум в потере файлов, записанных в течение последних минут, по идее, S.M.A.R.T. должен выдать алерты и дать возможность сбросить slog еще до того, как диск отвалится полностью
Что думаю на будущее
У меня есть 1.5ТБ фоток в /data/photos (писал, что там свалка) сейчас начал активно осваивать immich (для новых фоток уже года 1.5 использую, а вот старые пока особо не выгружал в него), вот думаю включить dedup для /data/immich, возможно надо будет гигов 10 добавить SSD туда чтобы в процессе перетаскивания фоток из /data/photos в immich эти фотки не занимали 2 раза место на моем массиве, а за счет дедупликации просто были ссылки на них.
В целом, дедупликация это не самая удачная вещь в плане производительности как добавляет еще один слой маппинга данных, но место экономит прилично
Последние замечания
- RAID не гарантирует сохранности данных, правило 3-2-1 не разрешает нам отказаться от классических бэкапов при хранении данных на RAID массиве, можно как минимум добавить синхрониацию с другими дисками, холодное хранилище на сменных дисках и синхронизацию с облаком
- У меня сейчас 4 пула в TrueNAS, с одной стороны это усложнение и увеличение количества SSD дисков, с другой стороны это позволяет лучше тюнить пулы в зависимости от нагрузки + увеличить количество IOPS, так QBT с огромным iowait и очередью в секундых никак на влияет на работу других пулов, а бэкапирование я тоже не ограничивал по скорости т.к. интентивная запись бэкапов не влияет на скорость доступа к фоткам и git