Столкнулся со следующими неудобствами/проблемами
- Имеется несколько серверов с дисками, просматривать значения мониторинга в одном месте не очень удобно
- Некоторые USB адаптеры не показывают smart в автоматическом режиме, но если указать тип, то работают
- Хочется наглядности и централизованности
- вTrueNAS пока что у меня пробрасываются диски, а не контроллеры, мониторинг в нем не работает
Нашел один из нескольких проектов: scrutiny
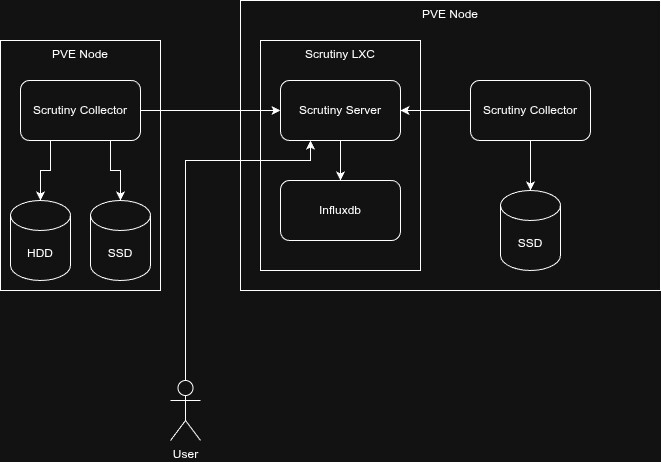
Проект состоит их 3 частей
- База данных для исторических данных и графиков
- Веб интерфейс, который отображает информацию
- Коллектор, который собирает информацию, он может быть в одном docker образе или же отдельно под разные платформы
Что я сделал
- Поднял LXC/Docker сервис с базой данных и веб интерфейсом
- Установил бинарник коллектора на PVE ноды
- Опубликовал веб интерфейс с proxy-auth
Пошагово
Прописал doc1ker-compose на сервере
services:
influxdb:
volumes:
- ./db:/var/lib/influxdb2
image: influxdb:2.2
restart: unless-stopped
scrutiny:
ports:
- 80:8080
volumes:
- ./scrutiny:/opt/scrutiny/config
image: ghcr.io/analogj/scrutiny:master-web
restart: unless-stopped
Создал конфиг scrutiny/scrutiny.yaml на основе шаблона, но задал адрес influxdb базы
influxdb:
# scheme: 'http'
host: influxdb
После запуска на 80 порту получил пустой дашборд + базу данных
Далее, пока в ручном режиме на PVE нодах
wget https://github.com/AnalogJ/scrutiny/releases/download/v0.8.1/scrutiny-collector-metrics-linux-amd64 -O /usr/local/bin/scrutiny-collector-metrics
mkdir /etc/scrutiny
vim /etc/scrutiny/collector.yaml
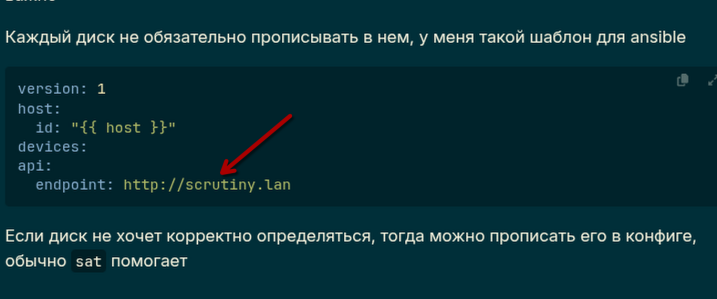
и вставил следующий файл (шаблон)
version: 1
host:
id: "PVE-05"
devices:
- device: /dev/sda
type: `sat`
api:
endpoint: http://scrutiny.lan
Соответственно, прописываем название хоста, переопределение типа диска и хост веб интерфейса, который развернули ранее
vim /etc/cron.d/sсrutiny
Вставляем
# scrutiny SMART collector
PATH="/usr/sbin:/usr/bin:/sbin:/bin"
*/10 * * * * root if [ -f /etc/scrutiny/collector.yaml ] ;then /usr/local/bin/scrutiny-collector-metrics run --config=/etc/scrutiny/collector.yaml --log-file /var/log/scrutiny-collector.log > /dev/null 2>&1; fi
Тут прописываем расписание запуска и пути
Коллектор запускается, собирает информацию всю, отправляет ее на сервер и завершает свою работу
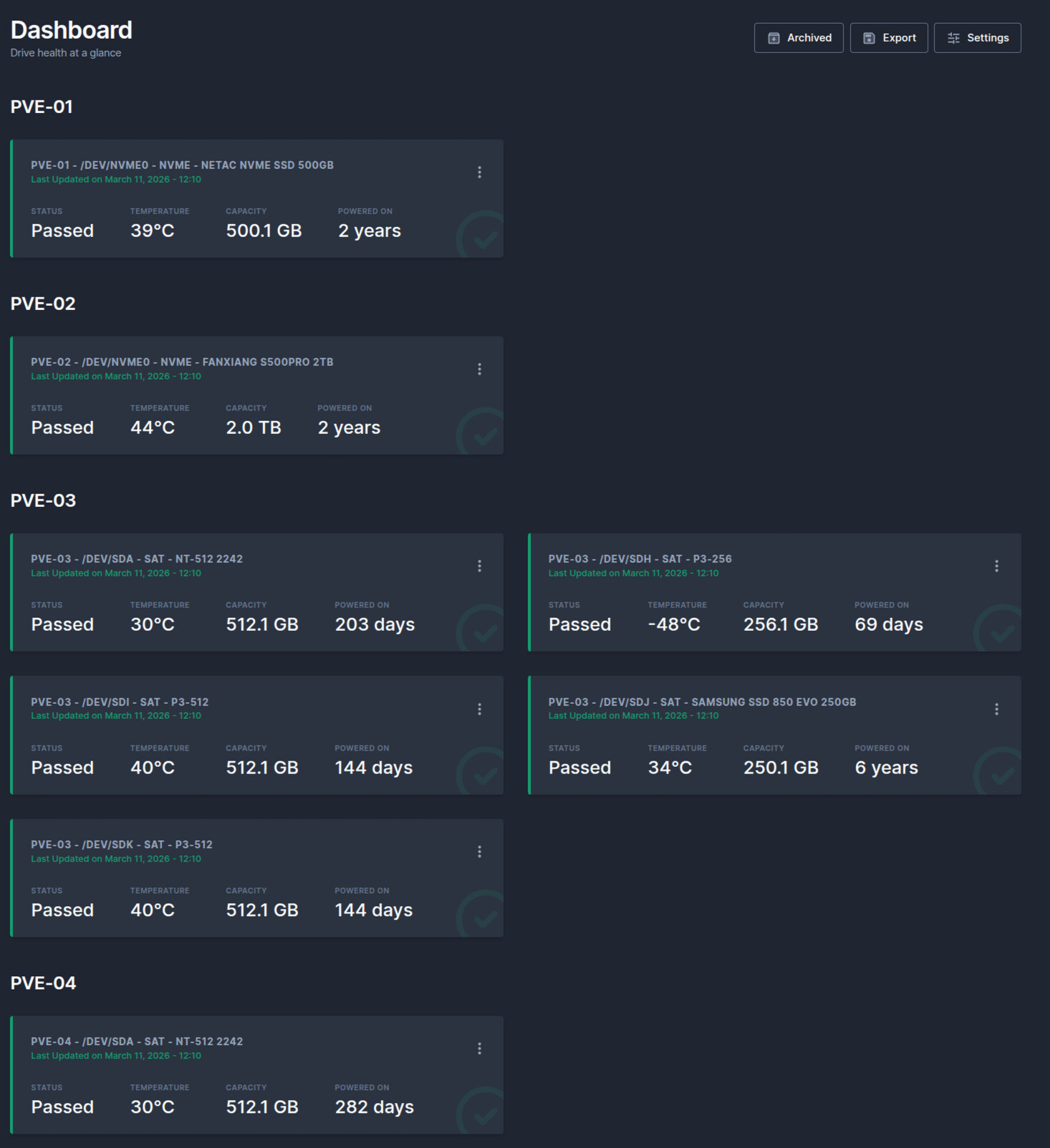
Скриншоты
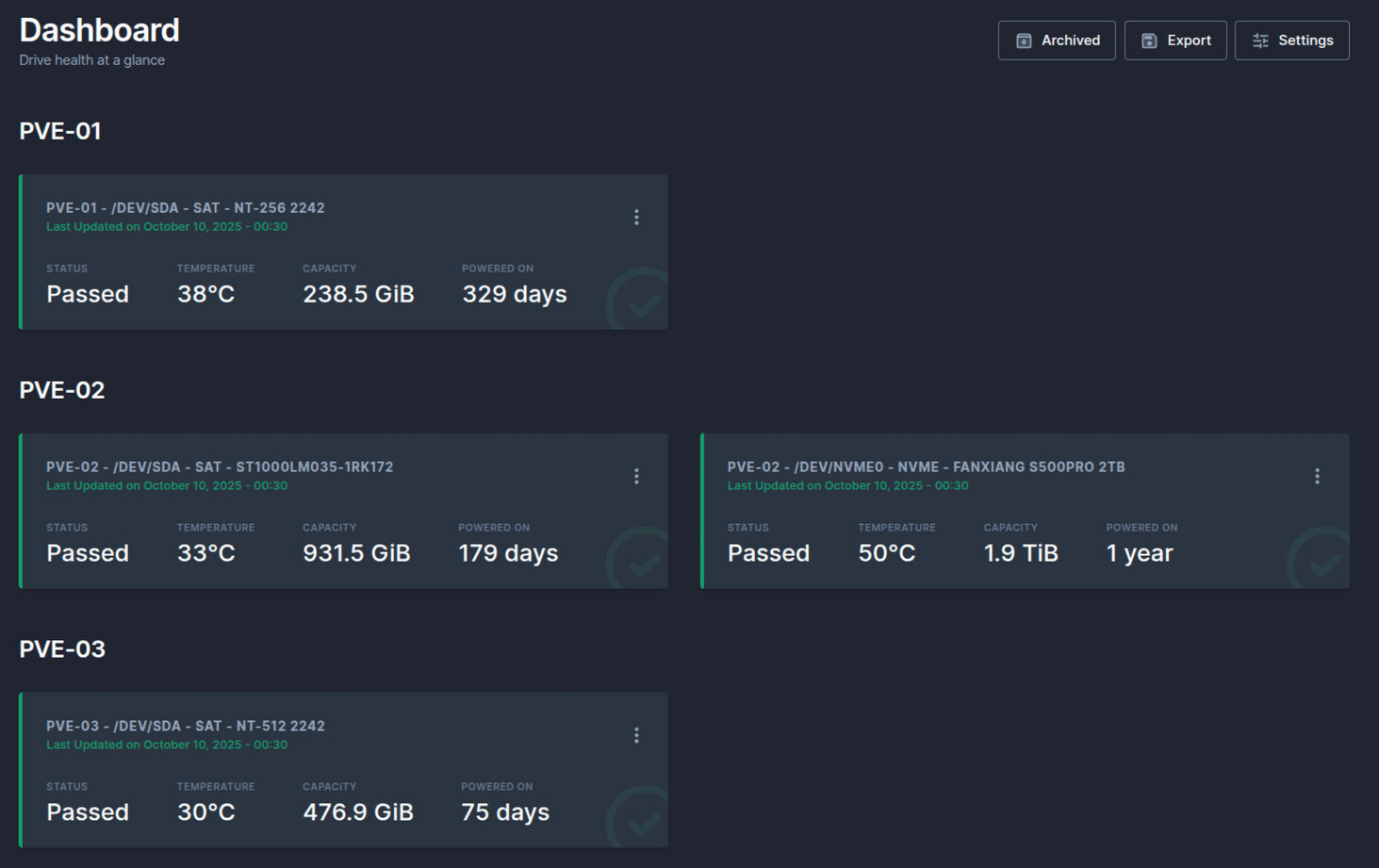
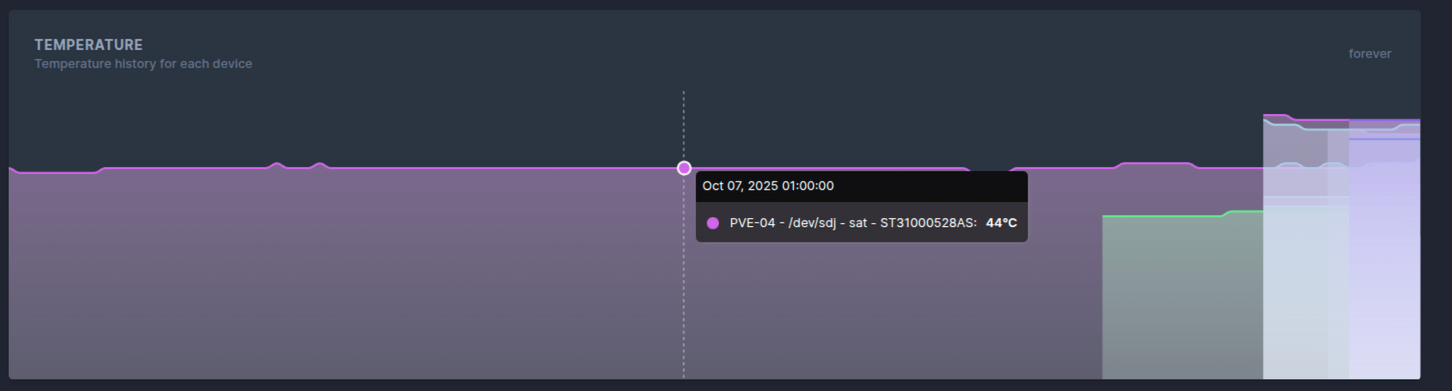
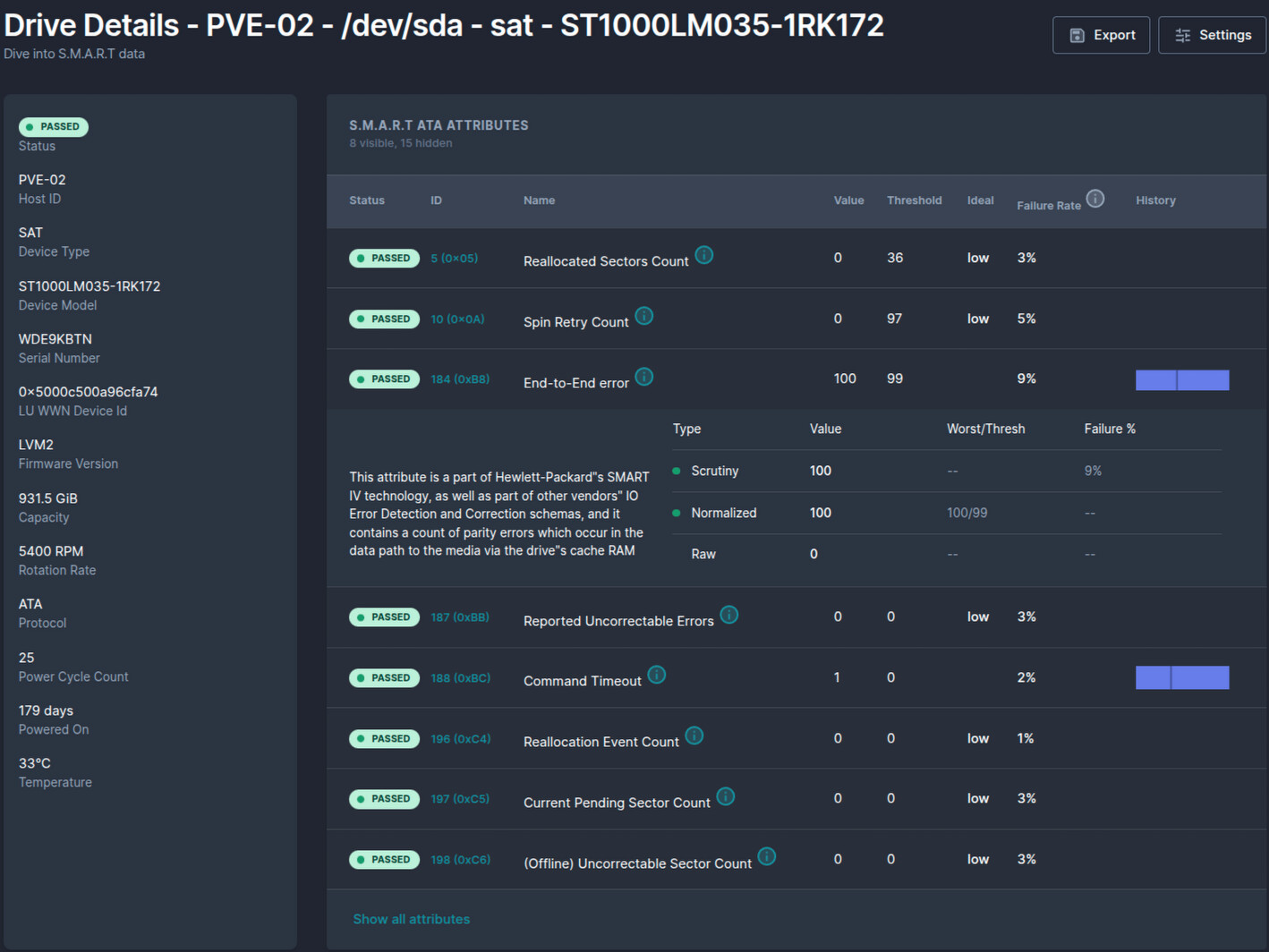
Уведомления есть в шаблоне scrutiny
#notify:
# urls:
# - "discord://token@webhookid"
# - "telegram://token@telegram?channels=channel-1[,channel-2,...]"
# - "pushover://shoutrrr:apiToken@userKey/?priority=1&devices=device1[,device2, ...]"
# - "slack://[botname@]token-a/token-b/token-c"
# - "smtp://username:password@host:port/?fromAddress=fromAddress&toAddresses=recipient1[,recipient2,...]"
# - "teams://token-a/token-b/token-c"
# - "gotify://gotify-host/token"
# - "pushbullet://api-token[/device/#channel/email]"
# - "ifttt://key/?events=event1[,event2,...]&value1=value1&value2=value2&value3=value3"
# - "mattermost://[username@]mattermost-host/token[/channel]"
# - "ntfy://username:password@host:port/topic"
# - "hangouts://chat.googleapis.com/v1/spaces/FOO/messages?key=bar&token=baz"
# - "zulip://bot-mail:bot-key@zulip-domain/?stream=name-or-id&topic=name"
# - "join://shoutrrr:api-key@join/?devices=device1[,device2, ...][&icon=icon][&title=title]"
# - "script:///file/path/on/disk"
# - "https://www.example.com/path"
Что понравилось
- Вроде даже есть какя-то хронология, а не просто показ данных
- Можно переопределять тип диска, что полезно очень т.к. proxmox показывает, что нет smart у диска, а по факту он есть
- Я так понял, что диски по серийникам создаются, при переезде диска в другой сервер он переезжает с сохранением данных, но у меня iscsi диск один выводился т.е. он есть на всех серверах, но выводится последний привязаный
- Можно скрыывать диски
- Написан на go, очень быстрый
- Современный дизайн и темная тема
Что не понравилось
- Похоже, что проект мертвый: написано, что бета, но последняя сборка была в апреле 24 года, куча ишьюсов и пулреквестов
- Тип диска определяется по букве, соответственно, при смене оной конфигурация поплывет
- Никакой безопасности: ни аутентификации веб интерфейса, ни коллекторов
- Проект сырой, графиков маловато, функционал базовый
- Были заготовки под самотесты дисков, но данный функционал так и не был реализован
Что недоделал
- DEB пакет и/или Ansible плейбук для быстрого деплоя
- Закрытие фаерволом
- Форк и допиливание проекта
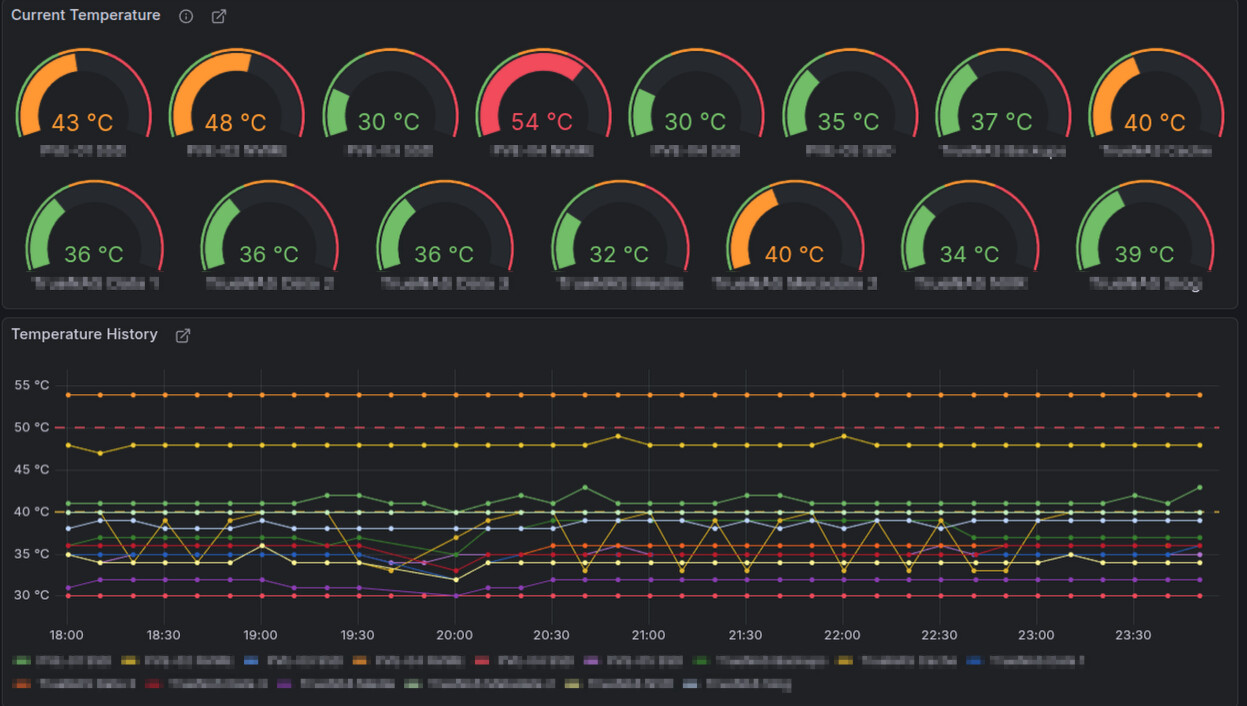
{kind=link}