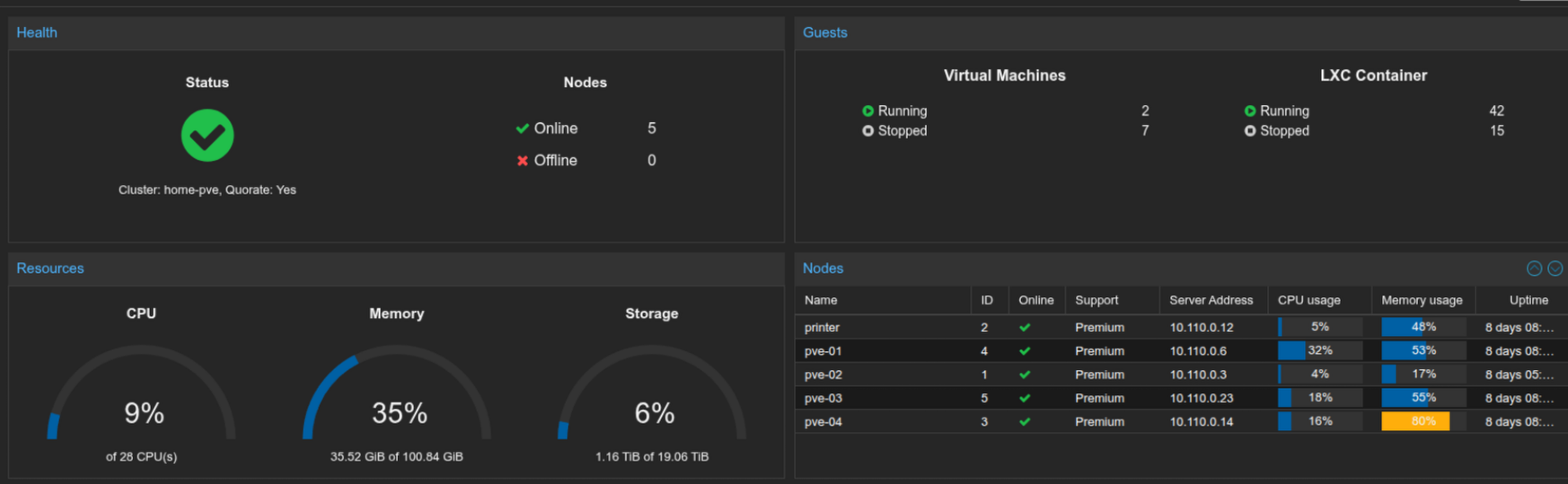
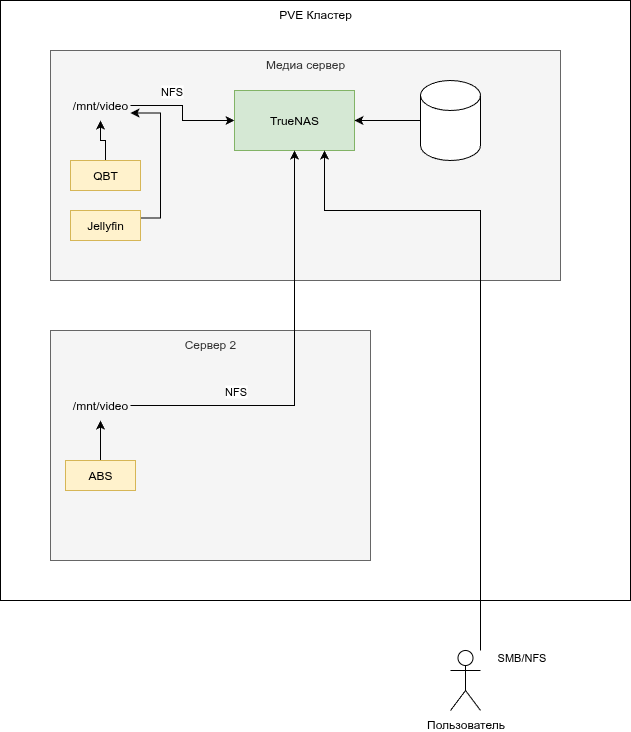
У меня сейчас диски проброшены в truenas не через PCI контроллер, а по одному, тем более, что сейчас подключены по USB, но на следующий год хочу минипк заменить на mini ITX плату именно под медиа сервак с truenas
Ну и еще думаю сделать раскатку fstab при помощи ansible, он будет одинаковый для всех серверов, т.к. даже на медиа ноде все равно по NFS монтируется.
А так да, явных причин не было, но я 100500 лет сидел на ручном шаринге путем правки smb.conf и /etc/exports + поднимал самбу на медиа контейнере с торрентами (на старте) и просто хотелось забить на все и делать клац клац мышкой
Я вообще ставил truenas, чтобы делать клац-клац, реально задолбался править уродские конфиги самбы, восстанавливать шары после обновления операционки, писать на баше скрипты для создания снепшотов zfs, какие-то уведомления настраивать, иметь 100500 программ под каждый тип шары, в общем, одной ногой уже наступил на Synology, но хотелось больше гибкости и не платить кучу денег за старое железо.
В итоге в TrueNAS собрал пулы, создал пользователей, настроил шары, настроил лимиты по датасетам и смотрю как оно все красиво отображется, правда, я начинал с core на FreeBSD, а потом понял, что это бесперспективная ветка и развернул Scale версию и был неприятно удивлен тем, что выпилили кучу протоколов из ядреной поставки, например, fto (который не пользую), tftp, webdav, afp, rsync, с приложениями не так прикольно уже настраивать шару, тогда уже можно и
по этому сценарию пойти