Всем привет.
Публикую эту заметку для тех, кому интересен вопрос самохостинга собственного экземпляра youtube.
Вопрос сохранения доступа к важным и ценным youtube-видео в нынешних реалиях стоит особенно остро.
В ходе поиска подходящего для этих целей сервиса остановился на opensource проекте TubeArchivist. Понравилось в этом проекте следующие:
- Возможность скачивать видео через свой webui
- Возможность скачивать видео через браузер посредством расширения (FireFox, Chrome)
- Возможность скачивать комментарии и субтитры к видео
- Предусмотрена каталогизация видео (в разрезе каналов)
- Можно формировать свои плейлисты
- Гибкая настройка и защита от блокировки со стороны youtube
![]() Будет многобукв поэтому разделю материал на 2 части:
Будет многобукв поэтому разделю материал на 2 части:
- Рекомендации по установке и настройке
- Кастомизация подхода по хранению файлов
Часть-1: Рекомендации по установке и настройке
Общая схема того, что будем реализовывать
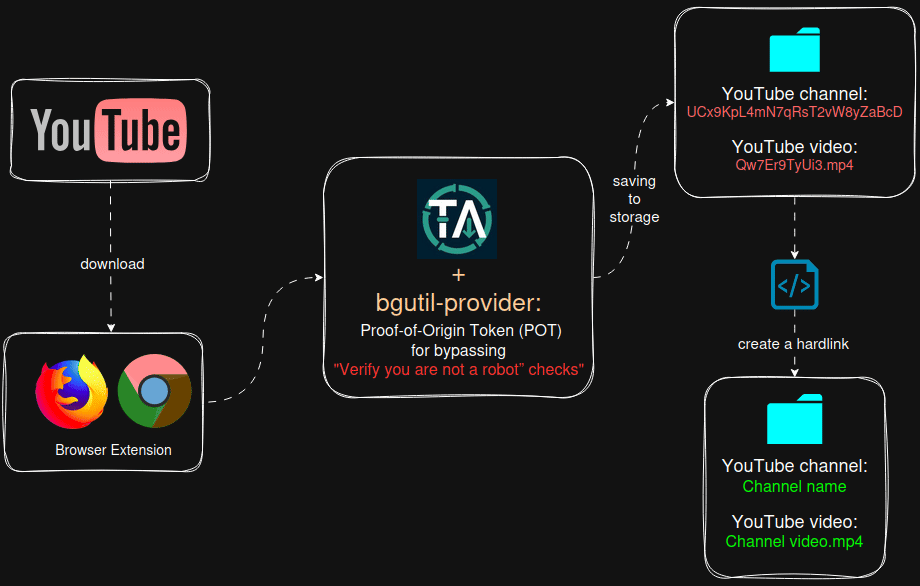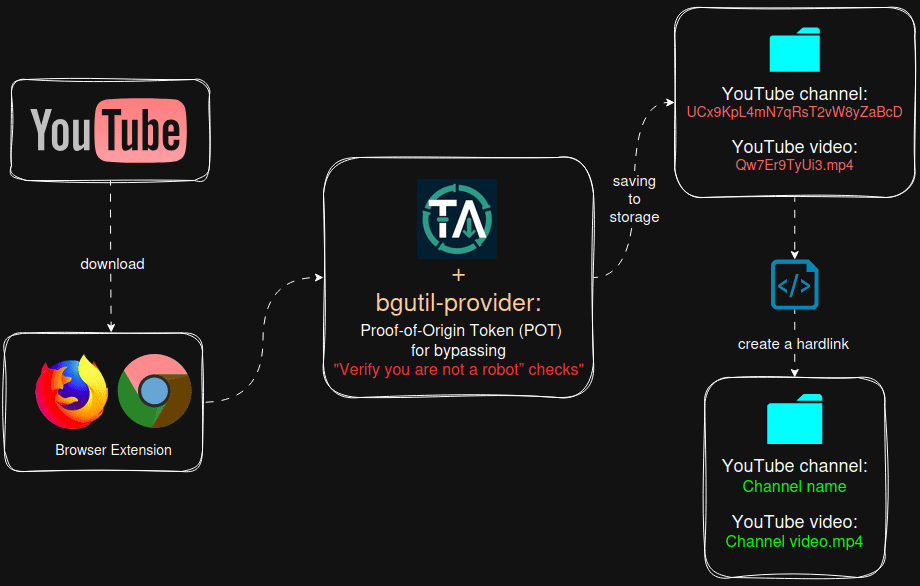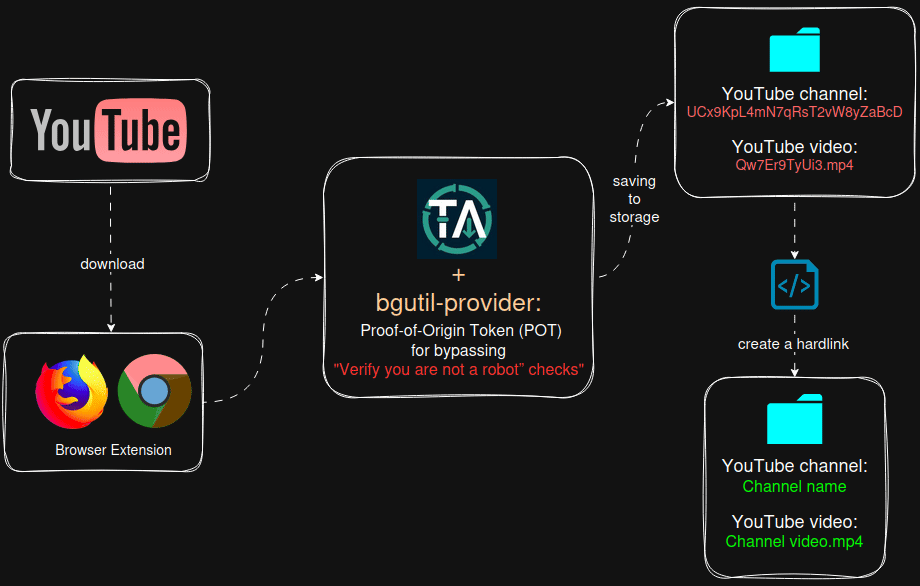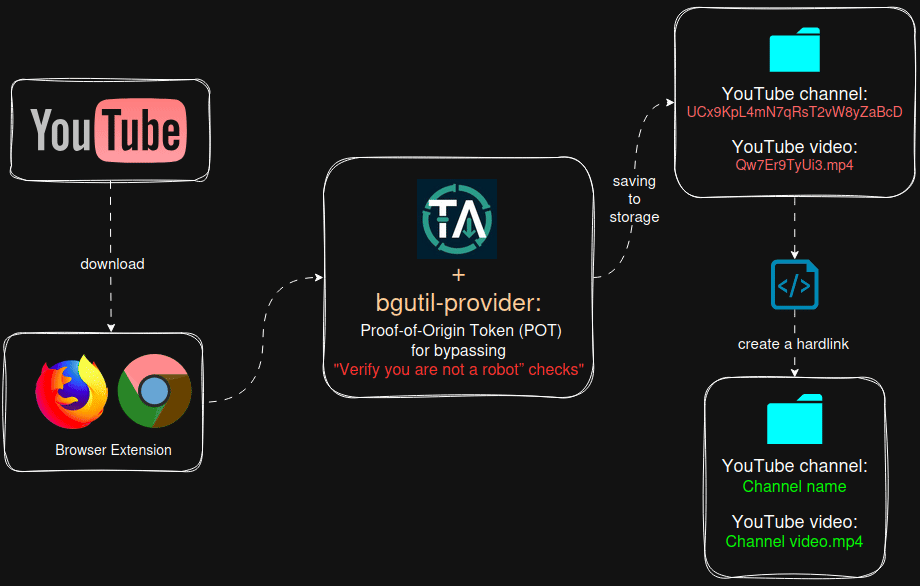
![]() Версии ПО:
Версии ПО:
PVE: 9.1.5
OS: Debian 13.1 (trixie)
Docker Engine: 28.5.1, build e180ab8
TubeArchivist: 0.5.9
![]() Ссылки:
Ссылки:
- Официальная документация
- Репозиторий Tube Archivist на GitHub
- Расширения для браузеров
- Видео от ProHomeLab
- Docker-compose от ProHomeLab
Изначально начинал настраивать сервис по видео и репозиторию товарища stilicho2011 (ProHomelab), но на сегодняшний день мануал немного устарел, поэтому будьте внимательны и сверяйте часы с официальной документацией.
 Настройка директорий в LXC:
Настройка директорий в LXC:
При настройке volumes исходил из того, что все настройки и кэши будут храниться в LXC с Tube Archivist, а медиа данные в NAS, в связи с чем структура директорий выглядит следющим образом:
Proxmox хост
└── /mnt/tubearchivist
└── youtube <-- NFS-директория с медиа-контентом на хосте PVE
(смонтирована в LXC)
LXC контейнер
├── /mnt/tubearchivist/youtube <-- смонтировано из Proxmox
│ └── (в Docker контейнер /youtube)
└── /opt/tubearchivist
├── cache <-- локальная, смонтирована в Docker /cache
├── redisdata <-- локальная, смонтирована в Docker /data
├── elasticsearch <-- локальная, смонтирована в Docker /usr/share/elasticsearch/data
└── script <-- служебная, не монтируется в Docker (опционально, см. 2-ю статьи)
![]() Важно!
Важно!
Для директори elasticsearch (сервис archivist-es) необходимо изменить владельца:
chown 1000:0 /opt/tubearchivist/elasticsearch
![]() Пример настройки прав:
Пример настройки прав:
root@TubeArchivist:/opt/tubearchivist# ls -lnh
total 16K
drwxr-xr-x 9 0 0 4.0K Feb 21 23:07 cache
drwxr-xr-x 6 1000 0 4.0K Feb 21 23:12 elasticsearch
drwxr-xr-x 2 0 0 4.0K Feb 21 22:46 redisdata
drwxr-xr-x 2 0 0 4.0K Feb 21 20:08 script
 Подготовка docker-compose
Подготовка docker-compose
![]() Рекомендованным способом установки является использование docker.
Рекомендованным способом установки является использование docker.
Ниже привожу пример своего docker-compose файла с комментариями. Ключевые изменения:
- Для сервиса tubearchivist задана опция запрета повышения привилегий
security_opt:
- no-new-privileges:true
- Для установки в непривилегированный LXC были закоментированы дефолтные лимиты для сервиса archivist-es:
# ulimits:
# memlock: ## позволяет контейнеру держать всю память в RAM без свопа (в unrivileged LXC не работает. Обходится отключение swap для LXC и выделение достаточного объёма RAM)
# soft: -1 ## в unrivileged LXC не работает!
# hard: -1 ## в unrivileged LXC не работает!
- Добавлен сервис bgutil-provider, который автоматически генеррирует PO Token Provider URL для обхода защиты “подтвердите, что вы не робот”. Youtube может определить загрузчик yt‑dlp как бота и заблокировать загрузку, для решения этой проблемы необходимо интегрировать в Tube Archivist данный сервис (ниже опишу, как настроить)
- Настройки с комментарием “
## !!!Задай своё значение!!!” необходимо настроить индивидуально под себя
![]() Docker-compose:
Docker-compose:
services:
tubearchivist:
container_name: tubearchivist
restart: unless-stopped
image: bbilly1/tubearchivist:latest
ports:
- 8000:8000
volumes:
- /mnt/tubearchivist/youtube:/youtube ## !!!Задай своё значение!!!
- /opt/tubearchivist/cache:/cache ## !!!Задай своё значение!!!
environment:
- ES_URL=http://archivist-es:9200 # needs protocol e.g. http and port
- REDIS_CON=redis://archivist-redis:6379
- HOST_UID=1000
- HOST_GID=1000
- TA_HOST=http://192.168.1.232:8000 # set your host name ## !!!Задай своё значение!!!
- TA_USERNAME=tubearchivist # your initial TA credentials
- TA_PASSWORD=verysecret # your initial TA credentials
- ELASTIC_PASSWORD=verysecret # set password for Elasticsearch
- TZ=Europe/Moscow ## !!!Задай своё значение!!!
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:8000/api/health/"]
interval: 2m
timeout: 10s
retries: 3
start_period: 30s
depends_on:
- archivist-es
- archivist-redis
security_opt:
- no-new-privileges:true
archivist-redis:
image: redis/redis-stack-server
container_name: archivist-redis
restart: unless-stopped
expose:
- "6379"
volumes:
- /opt/tubearchivist/redisdata:/data ## !!!Задай своё значение!!!
depends_on:
- archivist-es
archivist-es:
image: bbilly1/tubearchivist-es # only for amd64, or use official es 8.11.0
container_name: archivist-es
restart: unless-stopped
environment:
- "ELASTIC_PASSWORD=verysecret" # matching Elasticsearch password
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
- "xpack.security.enabled=true"
- "discovery.type=single-node"
- "path.repo=/usr/share/elasticsearch/data/snapshot"
# ulimits: ## memlock: -1 позволяет контейнеру держать всю память в RAM, без свопа (в unrivileged LXC не работает!)
# memlock: ##в unrivileged LXC не работает!
# soft: -1 ##в unrivileged LXC не работает!
# hard: -1 ##в unrivileged LXC не работает!
volumes:
- /opt/tubearchivist/elasticsearch:/usr/share/elasticsearch/data # check for permission error when using bind mount, see readme ## !!!Задай своё значение!!!
expose:
- "9200"
bgutil-provider: ## сервис для автоматической генерации PO Token Provider URL, позволяет обойти блокировку со стороны youtube.
image: brainicism/bgutil-ytdlp-pot-provider
container_name: bgutil-provider
restart: unless-stopped
init: true
expose:
- "4416"
![]() Важное уточнение по настройке сервиса tubearchivist.
Важное уточнение по настройке сервиса tubearchivist.
Для сервиса возможно задать две опции
- HOST_UID=1000
- HOST_GID=1000
Которые позволяют сервису сохранять файлы в примонтированную директорию с соответствующим uid:gid.
Здесь есть важное уточнение, что эти опции не имеют ничего общего с опцией user, которая позволяет запустить сервис внутри docker-контейнера от нужного вам uid:gid от которых будет производиться дальнейшая запись файлов.
Что происходит на самом деле. Сервис tubearchivist сначала от root:root сохраняет файлы в директорию, после чего выполняет chown и меняет uid:gid на указанные в docker-compose. Поэтому, если вы на своём NAS установите любые отличные от 0:0 (root:root) uid:gid для директории, куда tubearchivist будет складывать медиа, то получите ошибку Permission denied.
Настройка webui
Здесь опишу те настройки, которые мне показались наиболее полезными (полное описание смотрите официальной доке).
- Авторизация
1.1 Сервис доступен по адресу, который вы задали в docker-compose. Пример:
- TA_HOST=http://192.168.1.232:8000 # set your host name ## !!!Задай своё значение!!!
1.2 Логин и пароль так же смотрите в docker-compose:
- TA_USERNAME=tubearchivist # your initial TA credentials
- TA_PASSWORD=verysecret # your initial TA credentials
- Settings → Application (это пример моих настроек, не претендую на истину!)
 Секция Downloads
Секция Downloads
2.1 Download Speed limit →2048(KB/s, ограничение скорости минимизирует риск блокировки со стороны youtube)
2.2 Throttled rate limit →100(перезапуск загрузки, если скорость упала ниже заданного порога KB/s)
2.3 Sleep interval →10(sec, интервал между повторными запросами минимизирует риск блокировки со стороны youtube)
Секция Download Format
2.4 Select download format for yt-dlp → если оставить пустым, то yt-dlp будет загружать наилучшее доступное качество, как правило, это эквивалентно использованию-f bestvideo*+bestaudio/best
2.5 Embed metadata → включитьOn(встраивает метаданные непосредственно в медиа-файл в виде меток, чуть больше времени на обработку при скачивании, но файл становится самодостаточным и метаданные могут быть прочитаны сторонними плеерами)
Секция Subtitles
2.6 Choose subtitle language →en,ru(указать язык субтитров для скачивания)
2.7 Enable auto generated subtitles → включитьOn(добавляет сгенерированные сабы в качестве запасного варианта к ручным сабам с youtube)
2.8 Enable subtitle index → есливключить, то будет индексация субтитров в elasticsearch для последующего поиска по ним, требовательно к железу, включать на своё усмотрение
Секция Comments
2.9 Index comments →all,100,all,30,all(получить максимум 100 родительских сообщений и максимум 30 ответов на них на любой глубине. Это невероятно крутая опция, т.к. в комментариях бывает очень ценная информация)
2.10 Comment sort method →sort comments by top
 Секция Cookie (ВАЖНО!!!)
Секция Cookie (ВАЖНО!!!)
2.11 PO Token Provider URL →http://bgutil-provider:4416(предварительно должен быть поднят docker-конейтейнер с сервисом автогенерации PO Token Providerbgutil-provider. Адрес и порт могут быть другими, если вы меняли соответствующие поля в docker-compose)
Проверка:
Чтобы убедиться в корректной интеграции между Tube Archivist и bgutil-provider необходимо поставить на загрузку одно видео, после чего открыть лог docker-контейнера bgutil-provider либо в вашем docker-менеджере либо выполнить команду в LXC:
docker logs -f bgutil-provider
Ключевое, что примерно должно быть в логе:
1. Started POT server (v1.2.2) on on address [::]:4416 -> ✅ Сервер запущен
2. Using challenge from /att/get -> ✅ TubeArchivist обратился к bgutil-provider, который в свою очередь запросил challenge у YouTube. Значит интеграция работает.
3. Generated IntegrityToken: {...} -> ✅ YouTube принял запрос, IntegrityToken успешно получен, TTL 43200 секунд (≈12 часов)
4. Generating POT for ... -> ✅ TubeArchivist передал ID видео, bgutil-provider сгенерировал валидный PO Token, yt-dlp использует его для скачивания.
- Settings → Scheduler
Обратите внимание на дефолтные настройки. Рекомендую сдвинуть все запланированные задания на период наименьшей нагрузки сервиса, к примеру:
3.1 Refresh Metadata →0 1 *(ежедневно в 1:00 ночи)
3.2 Thumbnail Check →30 1 *(ежедневно в 1:30 ночи)
Интеграция с браузером (на примере FireFox)
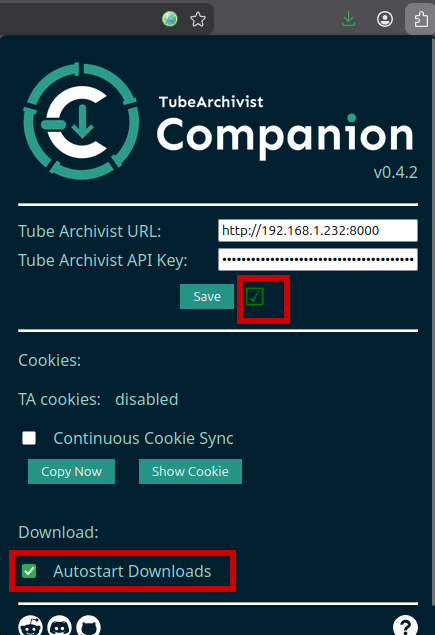
- Установить расширение Tubearchivist: ссылка
- Открыть расширение в браузере
2.1 Tube Archivist URL: →http://192.168.1.232:8000(указать адрес TA-сервиса, см. раздел Авторизация)
2.2 Tube Archivist API Key: → указатьAPI token(Tubearchivist → Settings → Application → Integrations → API token → Show → скопировать ключ)
2.3 Save (если всё в порядке, то будет гореть зелёная галочка)
2.4 Download: → установить чек бокс (после добавления видео в TA скачивание начнётся автоматически)
 Процесс скачивания
Процесс скачивания
Скачать видео можно двумя способами - непосредственно через интерфейс Tube Archivist или через расширение для браузера.
Рассмотрим оба способа.
![]() Самый простой и универсальный способ - это ручное добавление ссылки для скачивания в интерфейсе Tube Archivist.
Самый простой и универсальный способ - это ручное добавление ссылки для скачивания в интерфейсе Tube Archivist.
Добавляем ссылку для скачивания на вкладке Downloads → Add to download queue (если нужно, чтобы после добавления видео в очередь началась автоматическая загрузка, то включаем настройку “Auto Download”)
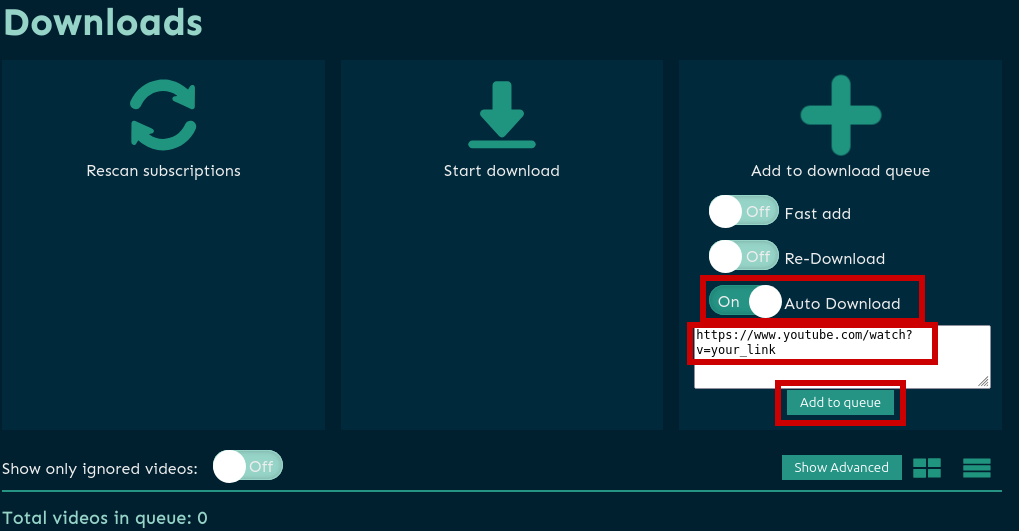
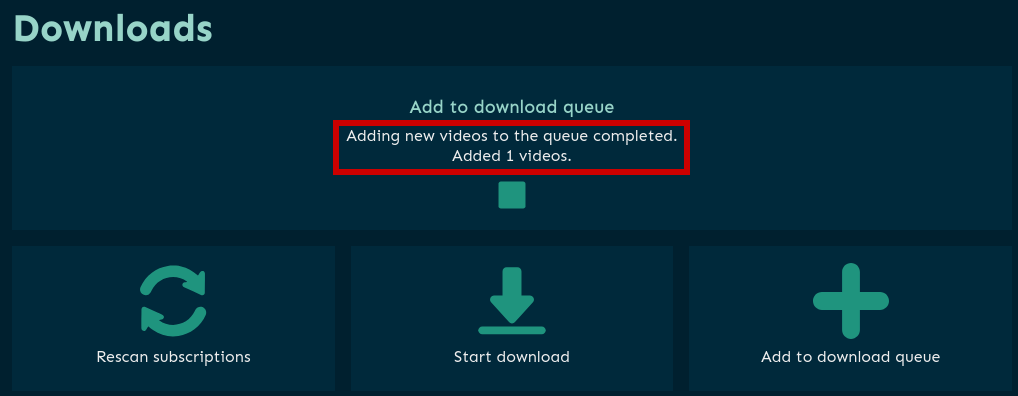
и жмём Add to queue, после чего процесс скачивания делится на 2 этапа:
- Подготовка очереди для скачивания
- Extracting URL
- Adding new videos to the queue completed
- Task completed
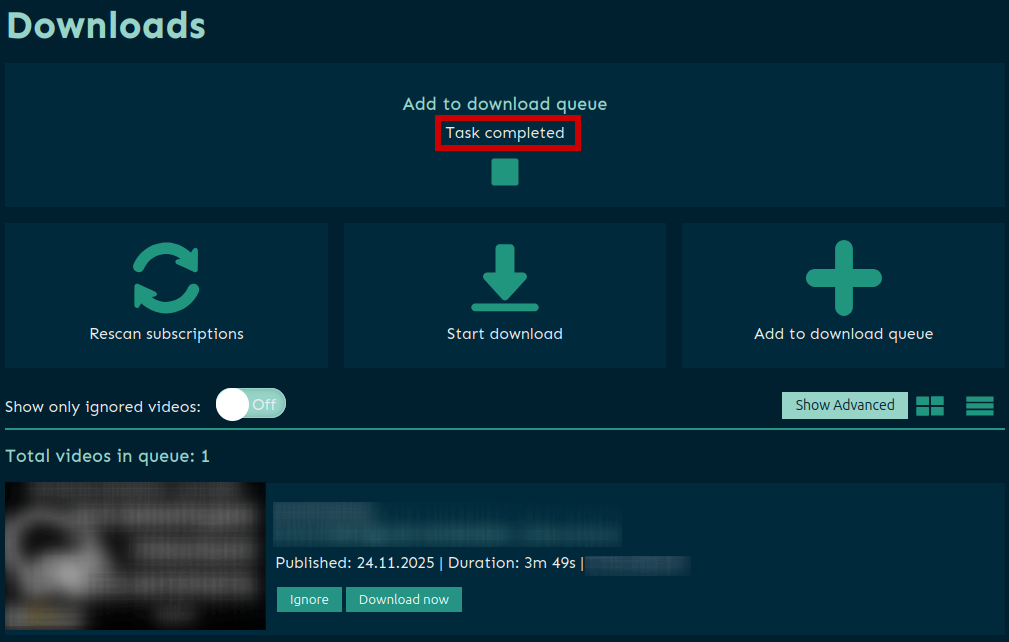
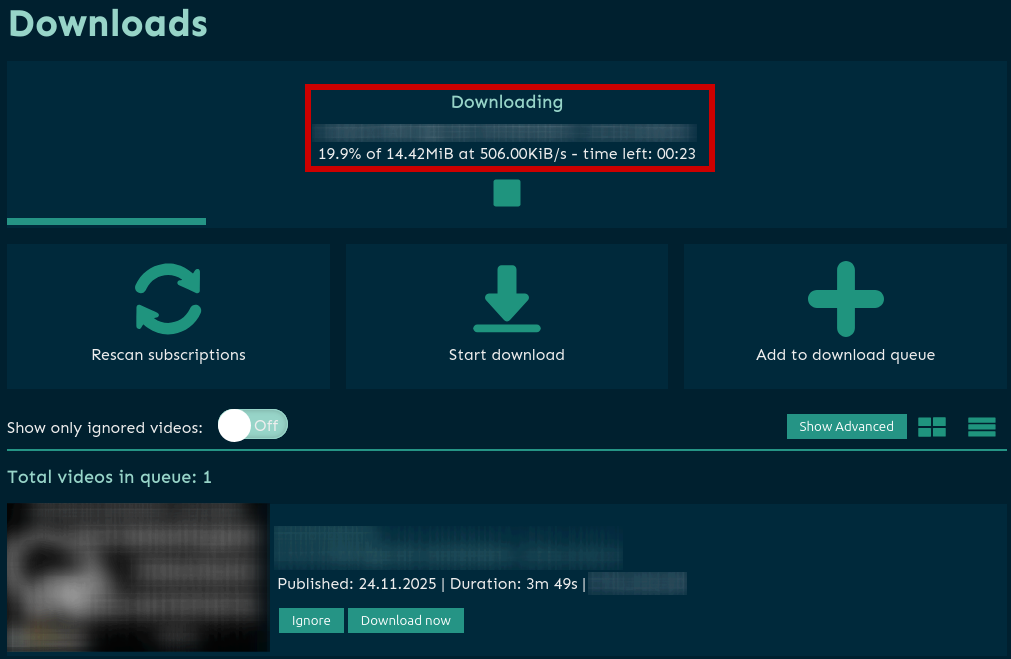
- Скачивание видео.
Жмём Start download или скачивание начинается автоматически, если на предыдщем шаге выставили соответствующую настройку:
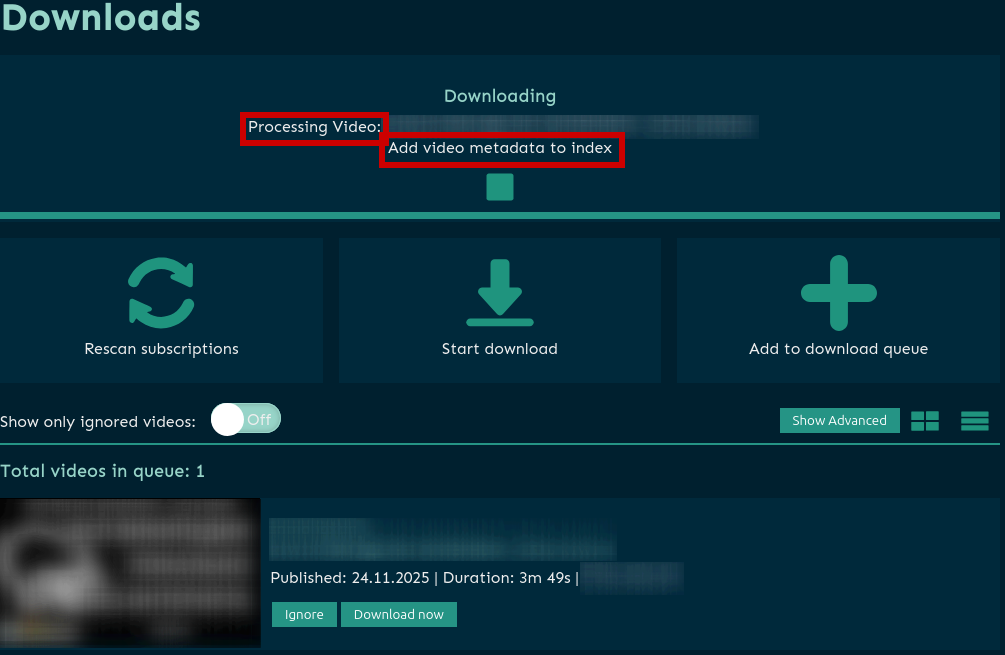
- Downloading (скачивание видео-файла)
- Processing Video (добавление метаданных в индекс Elasticsearch)
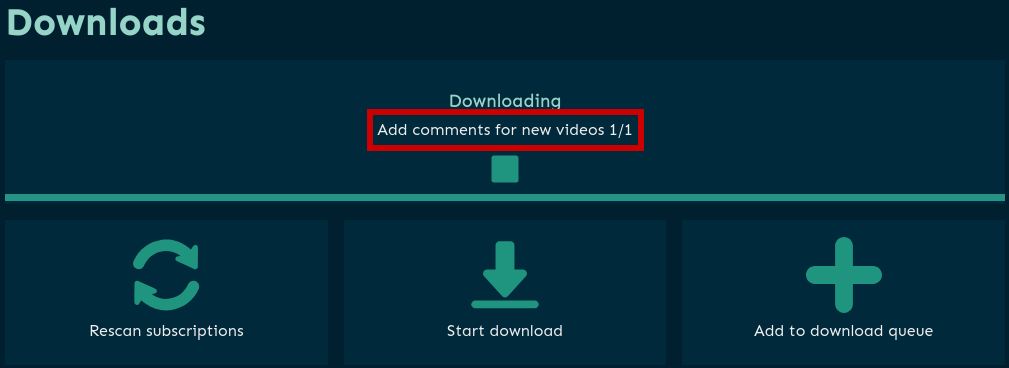
- Add comments for new videos (актуально, если эта опция включена в настройках, см. п.2.9-2.10)
- Task completed
![]() Скачивание через расширение для браузера FireFox или Chrome.
Скачивание через расширение для браузера FireFox или Chrome.
После установки расширения под видео на youtube появятся 2 активные кнопки Subscribe и Download.
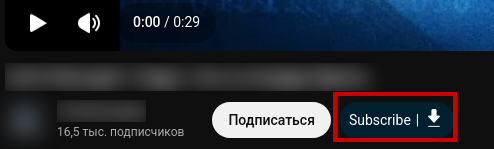
Здесь ничего хитрого - нажимаем, задание через API уходит в Tube Archivist после чего выполняется и в yotube меняется статус кнопок.
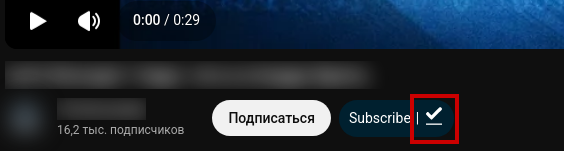
 Особенности интерфейса
Особенности интерфейса
Расскажу про некоторые неочевидные моменты в интерфейсе Tube Archivist, а именно про удаление видео, удаление каналов целиком со всеми видео, про корректную очистку очереди скачивания.
![]() Удаление видео
Удаление видео
Я не с первого раза разобрался, как удалить какое-нибудь видео. Если перейти на вкладку channels и открыть канал, то ниже будет список видео, которые сразу же можно воспроизвести, но меню для удаления отсутвует, как на странице канала, так и в плеере. Для этого необходимо открыть само видео (нажать по названию видео), после чего станут доступны различныые действия для видео, в т.ч. и удаление.

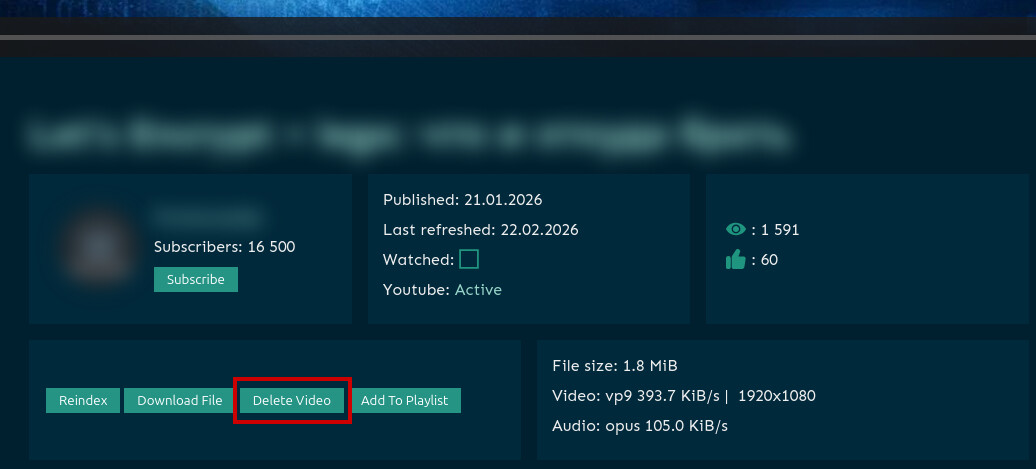
![]() Удаление канала
Удаление канала
Переходим на вкладку channels, открываем канал, который нужно удалить, переходим во вкладку About, находим кнопку Delete Channel → профит.
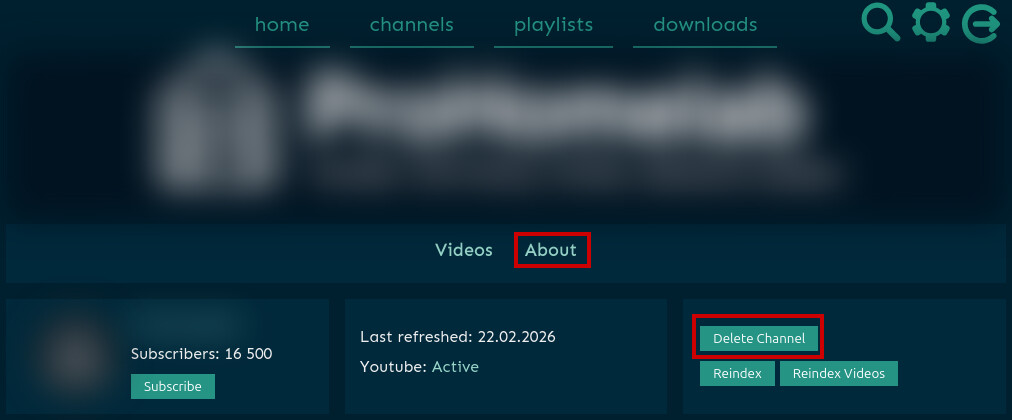
![]() Очистка очереди скачивания
Очистка очереди скачивания
После добавления видео в очередь для скачивания (при условии, что отключено автоматическое скачивание) его можно убрать из очереди, для этого необходимо нажать кнопку Ignore напротив видео. Если решите повторно добавить это видео в очерь для скачивания, то ничего не получится. По какой-то причине разработчик решил усложить такую простую функциональность.
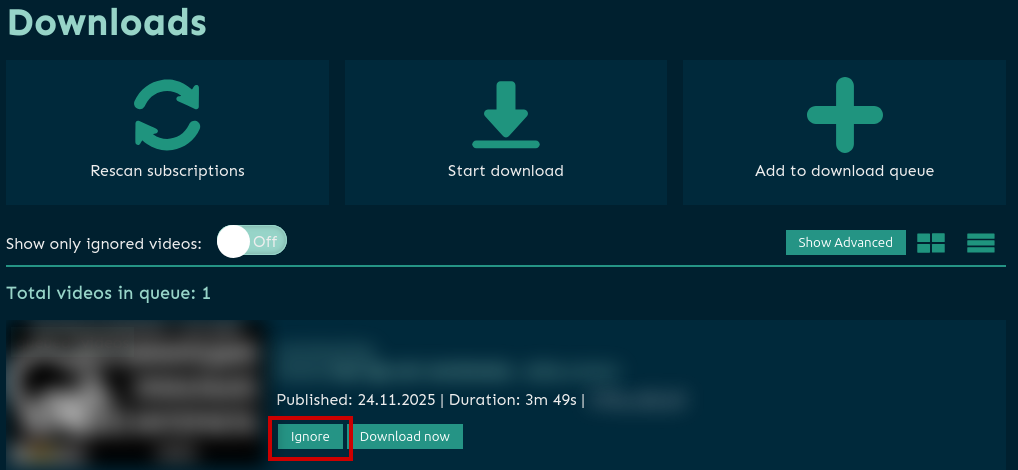
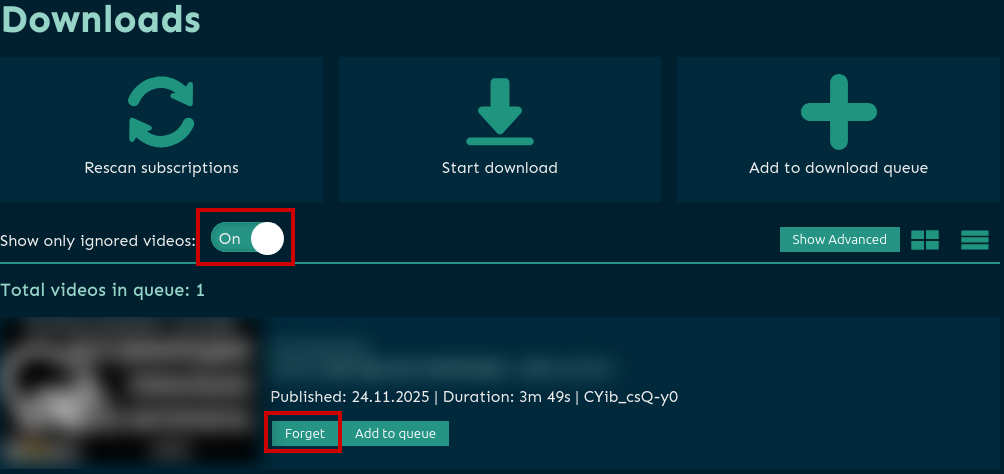
Дело в том, что после нажатия кнопки Ignore видео добавилось в список Ignore и дальнейшее добавление в очередь загрузки будет невозможно до того момента, пока мы не очистим список. Для этого необходимо на этой же странице найти и включить переключатель Show only ignored videos, после чего отобразится список видео в Ignore-листе. Для исключения из Ignore необходимо нажать на кнопку Forget напротив видео и вернуть переключатель Show only ignored videos в исходное значение.
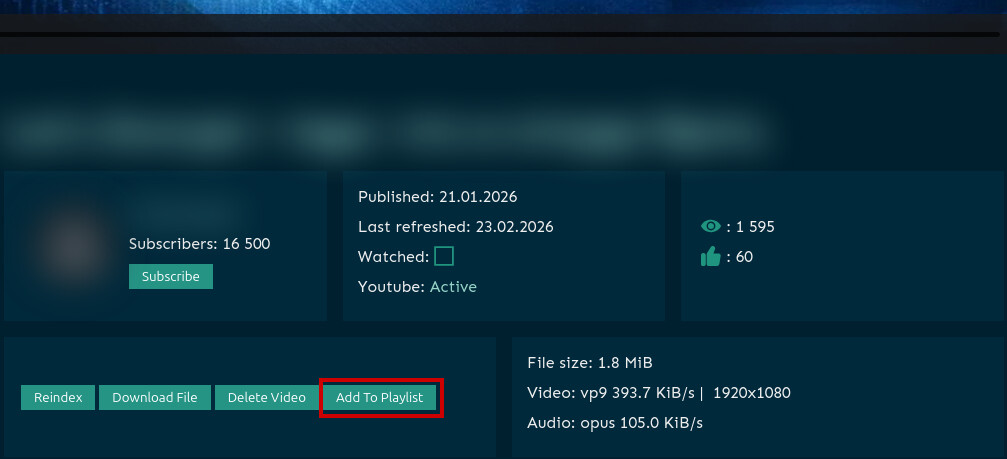
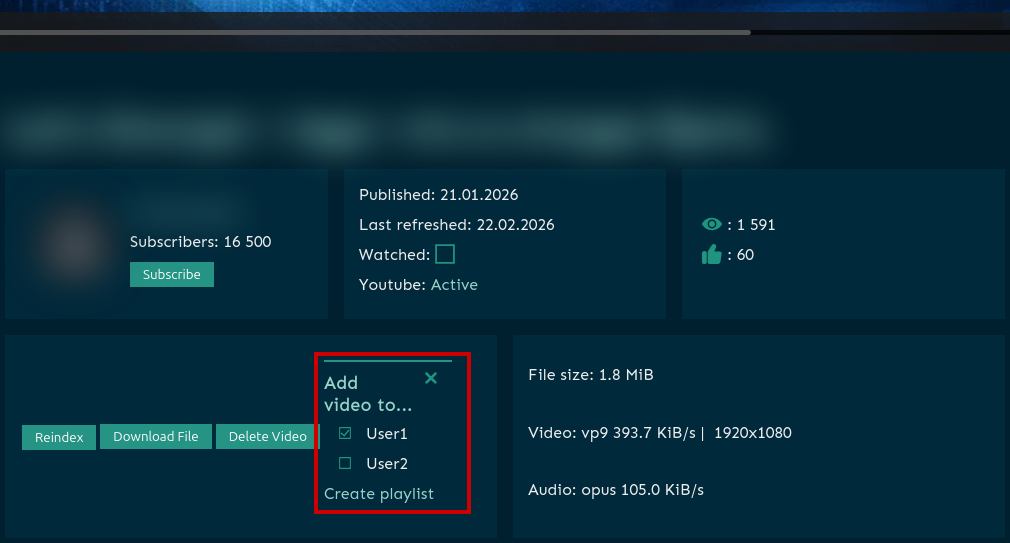
 Про многопользовательский режим
Про многопользовательский режим
В данный момент такая функциональность не реализована. Можно создать отдельного пользователя для ограничения доступа к настройкам приложения, но библиотека контетнта для всех пользователей будет общая.
В качестве обходного решения можно использовать плейлисты. К примеру создать плейлисты для User1 и User2 (вкладка playlists → значок + → Or create custom playlist → Create) и в настройках видео указать плейлист для нужного пользователя.
 Потребление ресурсов
Потребление ресурсов
Я выставил следующие параметры для LXC при которых сервис показывает стабильную работу:
Cores: 2
SWAP: 0
RAM: 4096 MB
Disk: 8Gb
Для полноты картины привожу значения основных метрик LXC после установки и запуска Tube Archivist:
CPU: 1%
RAM: 1,7GiB
Disk: 4,3GiB
Для примера сотояние LXC в момент скачивания и индексации видео:
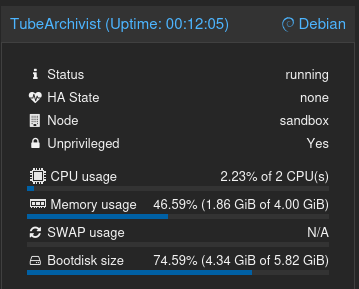
Утилизация дискового пространства
![]() Объём индексов и кэша сразу после установки Tube Archivist:
Объём индексов и кэша сразу после установки Tube Archivist:
--- /opt/tubearchivist ---
1.2 MiB [######################] /elasticsearch
232.0 KiB [#### ] /cache
8.0 KiB [ ] /redisdata
![]() Скачиваем 10 видео:
Скачиваем 10 видео:
root@TubeArchivist:~# ls -lnh /mnt/tubearchivist/youtube/UCxxxxxxxxxxxxxxxxxxxxxx/
total 637M
-rw-r--r-- 1 1000 1000 98M Feb 22 18:27 Ab3kLm9QwEr.mp4
-rw-r--r-- 1 1000 1000 47K Feb 22 17:59 Ab3kLm9QwEr.ru.vtt
-rw-r--r-- 1 1000 1000 38M Feb 22 18:27 Zx8CvBn2TyU.mp4
-rw-r--r-- 1 1000 1000 48K Feb 22 18:15 Zx8CvBn2TyU.ru.vtt
-rw-r--r-- 1 1000 1000 57M Feb 22 18:27 Qw7ErTy5UiO.mp4
-rw-r--r-- 1 1000 1000 45K Feb 22 18:06 Qw7ErTy5UiO.ru.vtt
-rw-r--r-- 1 1000 1000 94M Feb 22 18:27 Mn4BxZp9LsK.mp4
-rw-r--r-- 1 1000 1000 58K Feb 22 18:14 Mn4BxZp9LsK.ru.vtt
-rw-r--r-- 1 1000 1000 32M Feb 22 18:27 Rt6YuIo3PaS.mp4
-rw-r--r-- 1 1000 1000 47K Feb 22 18:24 Rt6YuIo3PaS.ru.vtt
-rw-r--r-- 1 1000 1000 49M Feb 22 18:27 Lk9JhGt2FdA.mp4
-rw-r--r-- 1 1000 1000 59K Feb 22 18:16 Lk9JhGt2FdA.ru.vtt
-rw-r--r-- 1 1000 1000 62M Feb 22 18:27 Vb5NmQw8ErT.mp4
-rw-r--r-- 1 1000 1000 54K Feb 22 18:07 Vb5NmQw8ErT.ru.vtt
-rw-r--r-- 1 1000 1000 73M Feb 22 18:27 Ht2YpLq7WsX.mp4
-rw-r--r-- 1 1000 1000 56K Feb 22 18:23 Ht2YpLq7WsX.ru.vtt
-rw-r--r-- 1 1000 1000 54M Feb 22 18:27 Kd8FsGh4JkL.mp4
-rw-r--r-- 1 1000 1000 63K Feb 22 17:57 Kd8FsGh4JkL.ru.vtt
-rw-r--r-- 1 1000 1000 85M Feb 22 18:27 Px3CvBn7MmN.mp4
-rw-r--r-- 1 1000 1000 51K Feb 22 18:02 Px3CvBn7MmN.ru.vtt
![]() Объём индексов и кэша после скачивания 10 видео:
Объём индексов и кэша после скачивания 10 видео:
--- /opt/tubearchivist ---
1.8 MiB [######################] /elasticsearch
1.3 MiB [################ ] /cache
20.0 KiB [ ] /redisdata
![]() Получилось 1,7 MiB служебных данных на 650 MiB медиа файлов, что примерно соответствует 2,7 GiB служебных данных на 1Tb медиа файлов. Учитывайте это при планировании объёма диска, выделяемого под LXC.
Получилось 1,7 MiB служебных данных на 650 MiB медиа файлов, что примерно соответствует 2,7 GiB служебных данных на 1Tb медиа файлов. Учитывайте это при планировании объёма диска, выделяемого под LXC.
Часть-2: Кастомизация подхода по хранению файлов
Tube Archivist при скачивании видео создаёт директорию (канал) и складывает в неё файлы с видео и метаданными. Все последющие видео с этого канала будут помещаться в эту же папку, такая же логика будет и для других каналов.
Директории присваивается не имя канала, а его ID, аналогично обстоит ситуация и для видео файлов. Пример структуры директорий и файлов:
/mnt/tubearchivist/youtube
├── UCx9KpL4mN7qRsT2vW8yZaBcD/ # ID канала
│ ├── Qw7Er9TyUi3.mp4 # Видео (ID видео)
│ ├── Qw7Er9TyUi3.ru.vtt # Метаданные видео
│ ├── Ab3Cd4Ef5Gh.mp4
│ └── Ab3Cd4Ef5Gh.ru.vtt
│
├── UCz1A2b3C4d5E6f7G8h9IjKl/
│ ├── Xy9Za8Bc7De.mp4
│ ├── Xy9Za8Bc7De.ru.vtt
│ └── ...
│
└── UCmNoPqRsTuVwXyZaBcDeFgH/
├── Lk8Ji7Hg6F.mp4
├── Lk8Ji7Hg6F.ru.vtt
└── ...
Это нужно для того, чтобы Tube Archivist остлеживал скаченные видео и не создавал дубли, а так же при подписке на канал отслеживал недостающие видео и скачивал их. ID у каналов и видео неизменны, поэтому решение разработчика вполне логично.
Мне захотелось иметь человекочитаемые названия директорий и файлов, для чего был написан скрипт с помощью ChatGPT, который создаёт рядом с директорией для хранения исходных youtube видео дополнительную директорию, в которую в виде hardlink-ов дублирует весь контент в человекочитаемом виде:
/mnt/tubearchivist/readable/ # целевая папка (hardlink-и)
├── Название Канала A/
│ ├── Как настроить Docker.mp4
│ ├── Как настроить Docker.ru.vtt
│ ├── Обзор LXC.mp4
│ └── Обзор LXC.ru.vtt
│
├── Название Канала B/
│ ├── Elasticsearch для начинающих.mp4
│ └── Elasticsearch для начинающих.ru.vtt
│
└── Название Канала C/
├── Введение в Redis.mp4
└── Введение в Redis.ru.vtt
![]() Что делает скрипт:
Что делает скрипт:
- Задаёт пути исходной (автоматически берёт volume для youtube из docker) и целевой (для hardlink-ов) папок, подключается к Elasticsearch, создаёт лог-файл
- Пишет лог с датой/временем в файл, держит последние N-записей
- Берёт список каналов и видео из Elasticsearch
- Создаёт целевые папки с читаемыми именами каналов
- Удаляет лишние папки и файлы, которых нет в источнике или Elasticsearch (при удалении видео или канала в Tube Archivist удаляется и hardlink)
- Создаёт hardlink файлов из исходной папки в целевую с «читаемыми» названиями
- Логирует окончание работы
![]() Схема алгоритма:
Схема алгоритма:
[tubearchivist-check.timer] ──every 5s──▶ [tubearchivist-check.service]
│
│ checks 📂 /mnt/tubearchivist/youtube
│ for changes
▼
┌─ if changes detected ──┐
│ │
[tubearchivist-debounce.timer] ──10s──▶ [tubearchivist.service]
│ │
│ │ runs make_readable_names.py
│ │ creates hard links in the
└────────────────────────┘ 📂 /mnt/tubearchivist/readable
![]() Как работает:
Как работает:
- Таймер
[tubearchivist-check.timer]каждые 5 секунд запускает сервис проверки[tubearchivist-check.service] - Сервис проверки запускает небольшорй bash скрипт
check_changes.sh, который проверяет изменения в исходной директории youtube - Если изменения не обнаружены, то ожидает следюушей инициации таймером через 5 секунд
- Если изменения обнаружены, то запускает таймер задержки
[tubearchivist-debounce.timer], который отсчитывает 10 секунд. Если в течение 10 секунд произошли ещё изменения в исходной директории youtube, то таймер задержки сбрасывается и отсчёт начинается сначала. Это нужно, чтобы исключить множественные запуски дальнейшей логики при массовых загрузках видео в Tube Archivist. После чего запускается сервис синхронизации[tubearchivist.service] - Сервис синхронизации
[tubearchivist.service]запускает python скриптmake_readable_names.py, который анализирует изменения и создаёт/удаляет в целевой директории с hardlink-ами директории файлы, выравнивая структуру с исходной директорией youtube
![]() Как запустить:
Как запустить:
- Создать файл в любой удобной для вас директории в LXC c Tube Archivist, например
nano /home/install.sh - Скопировать в него следующий код:
#!/bin/bash
set -e
STEP=1
SUMMARY=()
# -------------------------------
# 1. Checking Python3
# -------------------------------
if command -v python3 &>/dev/null; then
echo "✅ $STEP. Python3 is installed"
else
echo "🔎 $STEP. Python3 not found. Installing..."
apt update
apt install -y python3
echo "✅ $STEP. Python3 installation completed"
fi
SUMMARY+=("Step $STEP - Python check")
STEP=$((STEP+1))
# -------------------------------
# 2. Creating directory /opt/tubearchivist/script/
# -------------------------------
SCRIPT_DIR="/opt/tubearchivist/script"
mkdir -p "$SCRIPT_DIR"
echo "📁✅ $STEP. Directory $SCRIPT_DIR created (or already exists)"
SUMMARY+=("Step $STEP - Script directory ready")
STEP=$((STEP+1))
# -------------------------------
# 3. Creating file make_readable_names.py
# -------------------------------
PYTHON_FILE="$SCRIPT_DIR/make_readable_names.py"
echo "📝 $STEP. Creating file $PYTHON_FILE"
SUMMARY+=("Step $STEP - Preparing sync script")
STEP=$((STEP+1))
# -------------------------------
# 4. Filling in required variables
# -------------------------------
echo "⚙️ $STEP. Filling configuration variables..."
read -p "4.1 Enter the directory for hardlinks with readable names (optional, default name: readable). TARGET_ROOT: " TARGET_DIR_NAME
TARGET_DIR_NAME=${TARGET_DIR_NAME:-readable}
read -p "4.2 Enter the path for the log file (optional, default path: /opt/tubearchivist/script/). LOG_FILE: " LOG_FILE
LOG_FILE=${LOG_FILE:-/opt/tubearchivist/script/}
read -p "4.3 Enter the maximum number of lines in the log file (optional, default=100). LOG_MAX_LINES: " LOG_MAX_LINES
LOG_MAX_LINES=${LOG_MAX_LINES:-100}
echo "✅ Configuration variables set"
# =========================
# Auto-detect SOURCE_ROOT from archivist-es container
SOURCE_ROOT=$(docker inspect tubearchivist --format '{{range .Mounts}}{{if eq .Destination "/youtube"}}{{.Source}}{{end}}{{end}}')
if [ -z "$SOURCE_ROOT" ]; then
echo "❌ Failed to detect SOURCE_ROOT from Docker"
exit 1
fi
# =========================
# Calculate TARGET_ROOT (same logic as Python)
TARGET_ROOT="$(dirname "$SOURCE_ROOT")/$TARGET_DIR_NAME"
SUMMARY+=("Step $STEP - Configuration variables set")
STEP=$((STEP+1))
# -------------------------------
# 5. Populating make_readable_names.py
# -------------------------------
cat <<EOF | tee "$PYTHON_FILE" >/dev/null
####################
## The script synchronizes the folder and file structure of YouTube channels, converting “unreadable” file names into human-readable ones using data from Elasticsearch. Script structure:
## 1. Configuration: sets the target directory path for readable names and the log file path.
## 2. Logging: writes timestamped messages to the console and the log file, keeping only the last LOG_MAX_LINES entries.
## 3. Data retrieval: retrieves the list of channels and videos from Elasticsearch.
## 4. Folder preparation: creates target folders with readable channel names.
## 5. Cleanup: removes unnecessary folders and files that do not exist in the source or in Elasticsearch.
## 6. Synchronization: creates hard links from the source folder to the target folder using readable file names.
## 7. Completion: logs the end of execution.
####################
#!/usr/bin/env python3
import os
import re
import requests
import shutil
import subprocess
from pathlib import Path
from datetime import datetime
# =========================
# SETTINGS
# =========================
ES_USER = "elastic"
LOG_FILE = Path("$LOG_FILE")
LOG_MAX_LINES = $LOG_MAX_LINES
# If no file suffix → treat as directory
if LOG_FILE.suffix == "":
LOG_FILE = LOG_FILE / "tubearchivist_sync.log"
# Ensure parent directory exists
LOG_FILE.parent.mkdir(parents=True, exist_ok=True)
# =========================
# Auto-detect archivist-es container IP address
try:
ip = subprocess.check_output(
"docker inspect -f '{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}' archivist-es",
shell=True,
text=True
).strip()
ES_URL = f"http://{ip}:9200"
except subprocess.CalledProcessError:
print("Failed to retrieve the IP address of the archivist-es container")
ES_URL = "http://localhost:9200" # fallback
# =========================
# Auto-detect archivist-es container password
ES_PASSWORD = subprocess.check_output(
"docker inspect archivist-es --format '{{range .Config.Env}}{{println .}}{{end}}' | grep ELASTIC_PASSWORD | cut -d= -f2",
shell=True,
text=True
).strip()
# =========================
# Auto-detect archivist-es container bind volumes
SOURCE_ROOT = Path(subprocess.check_output(
"docker inspect tubearchivist --format '{{range .Mounts}}{{if eq .Destination \"/youtube\"}}{{.Source}}{{end}}{{end}}'",
shell=True,
text=True
).strip())
TARGET_DIR_NAME = "$TARGET_DIR_NAME"
TARGET_ROOT = SOURCE_ROOT.parent / TARGET_DIR_NAME
# =========================
# Helper function for logging
# =========================
def log(msg):
"""Logging with date/time and writing to a file, keeping only the last LOG_MAX_LINES lines"""
timestamp = datetime.now().strftime("%d.%m.%Y %H:%M:%S")
line = f"{timestamp} - {msg}"
print(line) # Console output
# If the log file does not exist, simply create it
if not LOG_FILE.exists():
try:
with LOG_FILE.open("w", encoding="utf-8") as f:
f.write(line + "\n")
except Exception as e:
print(f"Failed to write to the log: {e}")
return
# If the log file exists, read the current lines and append the new message
try:
with LOG_FILE.open("r", encoding="utf-8") as f:
lines = f.readlines()
except Exception as e:
print(f"Failed to read the log: {e}")
lines = []
lines.append(line + "\n")
# Keep only the last LOG_MAX_LINES
if len(lines) > LOG_MAX_LINES:
lines = lines[-LOG_MAX_LINES:]
try:
with LOG_FILE.open("w", encoding="utf-8") as f:
f.writelines(lines)
except Exception as e:
print(f"Failed to write to the log: {e}")
# =========================
def safe_name(name):
"""Remove forbidden characters"""
return re.sub(r'[<>:"/\\|?*]', '', name).strip()
def es_search(index, query):
r = requests.get(
f"{ES_URL}/{index}/_search",
auth=(ES_USER, ES_PASSWORD),
json=query,
)
r.raise_for_status()
return r.json()["hits"]["hits"]
def get_channels():
query = {"size": 10000, "query": {"match_all": {}}}
return es_search("ta_channel", query)
def get_videos(channel_id):
query = {
"size": 10000,
"query": {
"match": {"channel.channel_id": channel_id}
}
}
return es_search("ta_video", query)
def main():
TARGET_ROOT.mkdir(parents=True, exist_ok=True)
log("Scanning Elasticsearch...")
channels = get_channels()
# ==============================
# 1. Build a map channel_id → readable_name
# ==============================
channel_name_map = {}
for ch in channels:
ch_id = ch["_source"]["channel_id"]
ch_name = safe_name(ch["_source"]["channel_name"])
channel_name_map[ch_id] = ch_name
# ==============================
# 2. Removing unnecessary folders in TARGET
# ==============================
source_channel_ids = {
d.name for d in SOURCE_ROOT.iterdir() if d.is_dir()
}
for target_dir in TARGET_ROOT.iterdir():
if not target_dir.is_dir():
continue
# Checking if such a channel_id exists
found = False
for ch_id, ch_name in channel_name_map.items():
if target_dir.name == ch_name and ch_id in source_channel_ids:
found = True
break
if not found:
log(f"Removing the unnecessary directory: {target_dir}")
shutil.rmtree(target_dir)
# ==============================
# 3. Synchronizing each channel
# ==============================
any_changes = False
for ch_id in source_channel_ids:
source_channel_dir = SOURCE_ROOT / ch_id
# Channel name from ES or fallback to channel_id
ch_name = channel_name_map.get(ch_id, ch_id)
target_channel_dir = TARGET_ROOT / ch_name
if not target_channel_dir.exists():
log(f"Creating the channel directory: {target_channel_dir}")
target_channel_dir.mkdir(parents=True)
any_changes = True
videos = get_videos(ch_id)
video_map = {}
for video in videos:
vid_id = video["_source"]["youtube_id"]
vid_title = safe_name(video["_source"]["title"])
video_map[vid_id] = vid_title
valid_files = set()
new_files_added = False
# ==============================
# 4. Creating a hard link
# ==============================
for file in source_channel_dir.iterdir():
if not file.is_file():
continue
vid_id = file.name[:11]
suffix = file.suffix
readable_title = video_map.get(vid_id)
if readable_title:
target_file = target_channel_dir / f"{readable_title}{suffix}"
else:
# Fallback if the video is not in ES
target_file = target_channel_dir / file.name
valid_files.add(target_file.name)
if not target_file.exists():
os.link(file, target_file)
log(f"File added: {target_file}")
new_files_added = True
# ==============================
# 5. Removing unnecessary files
# ==============================
removed_any_file = False
for target_file in target_channel_dir.iterdir():
if target_file.is_file() and target_file.name not in valid_files:
target_file.unlink()
removed_any_file = True
log(f"Removing the unnecessary file: {target_file}")
if new_files_added or removed_any_file:
any_changes = True # Marking that changes occurred
if not any_changes:
log(f"No changes occurred in the {TARGET_ROOT} directory")
log("Done ✔")
if __name__ == "__main__":
main()
EOF
echo "🔄✅ $STEP. Directory synchronization script created"
SUMMARY+=("Step $STEP - Sync script created")
STEP=$((STEP+1))
# -------------------------------
# 6. Creating a file check_changes.sh
# -------------------------------
CHECK_FILE="$SCRIPT_DIR/check_changes.sh"
cat > "$CHECK_FILE" <<EOF
#!/bin/bash
WATCH_DIR="$SOURCE_ROOT"
STATE_FILE="/run/tubearchivist.state"
# Collecting a list of files and directories
CURRENT_STATE=\$(find "\$WATCH_DIR" -printf "%P %s %T@\\n" 2>/dev/null | sort)
# First run (initialization)
if [ ! -f "\$STATE_FILE" ]; then
echo "\$CURRENT_STATE" > "\$STATE_FILE"
# Immediately trigger first sync
systemctl restart tubearchivist-debounce.timer
exit 0
fi
PREV_STATE=\$(cat "\$STATE_FILE")
if [ "\$CURRENT_STATE" != "\$PREV_STATE" ]; then
echo "\$CURRENT_STATE" > "\$STATE_FILE"
# Trigger debounce timer
systemctl restart tubearchivist-debounce.timer
fi
EOF
echo "📄✅ $STEP. Check script created"
SUMMARY+=("Step $STEP - Check script created")
STEP=$((STEP+1))
# -------------------------------
# 8. Make executable
# -------------------------------
chmod 700 "$CHECK_FILE"
echo "🔐✅ $STEP. Made the check script executable = 700"
SUMMARY+=("Step $STEP - Permissions set")
STEP=$((STEP+1))
# -------------------------------
# 9. Creating systemd service tubearchivist-check.service
# -------------------------------
SERVICE_FILE="/etc/systemd/system/tubearchivist-check.service"
cat <<EOF | tee "$SERVICE_FILE" >/dev/null
[Unit]
Description=Check NFS changes for Tubearchivist
[Service]
Type=oneshot
ExecStart=$CHECK_FILE
EOF
echo "⚙️✅ $STEP. Check service created"
SUMMARY+=("Step $STEP - Check service created")
STEP=$((STEP+1))
# -------------------------------
# 10. Creating timer tubearchivist-check.timer
# -------------------------------
TIMER_FILE="/etc/systemd/system/tubearchivist-check.timer"
cat <<EOF | tee "$TIMER_FILE" >/dev/null
[Unit]
Description=Poll NFS for Tubearchivist changes
[Timer]
OnBootSec=5s
OnUnitActiveSec=5s
AccuracySec=1s
Unit=tubearchivist-check.service
[Install]
WantedBy=timers.target
EOF
echo "⏱️✅ $STEP. Check timer (every 5 seconds) created"
SUMMARY+=("Step $STEP - Check timer created")
STEP=$((STEP+1))
# -------------------------------
# 11. Creating debounced timer
# -------------------------------
DEBOUNCE_FILE="/etc/systemd/system/tubearchivist-debounce.timer"
cat <<EOF | tee "$DEBOUNCE_FILE" >/dev/null
[Unit]
Description=Debounced Tubearchivist execution
[Timer]
OnActiveSec=10s
AccuracySec=1s
Unit=tubearchivist.service
[Install]
WantedBy=timers.target
EOF
echo "⏳✅ $STEP. Debounce timer created"
SUMMARY+=("Step $STEP - Debounce timer created")
STEP=$((STEP+1))
# -------------------------------
# 12. Creating synchronization service
# -------------------------------
SYNC_SERVICE_FILE="/etc/systemd/system/tubearchivist.service"
cat <<EOF | tee "$SYNC_SERVICE_FILE" >/dev/null
[Unit]
Description=Run Tubearchivist sync script
[Service]
Type=oneshot
ExecStart=/usr/bin/python3 $PYTHON_FILE
EOF
echo "🔄✅ $STEP. Synchronization service created"
SUMMARY+=("Step $STEP - Sync service created")
STEP=$((STEP+1))
# -------------------------------
# 13. Executing systemctl commands
# -------------------------------
echo "🚀 $STEP. Activating systemd services..."
systemctl daemon-reload
systemctl enable --now tubearchivist-check.timer
systemctl enable tubearchivist-debounce.timer
systemctl status tubearchivist-check.timer || true
systemctl status tubearchivist-debounce.timer || true
echo "✅ Services successfully enabled"
SUMMARY+=("Step $STEP - Services activated")
# -------------------------------
# 14. Displaying final message
# -------------------------------
echo ""
echo "━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━"
echo "🎉 SYNCHRONIZATION SETUP COMPLETED"
echo "━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━"
echo ""
echo "📊 Summary:"
echo "--------------------------------------"
for item in "${SUMMARY[@]}"; do # NEW: выводим таблицу
printf " %-45s %s\n" "$item" "✅"
done
echo "━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━"
echo "Total steps executed: $STEP"
echo "━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━"
echo ""
echo "🆕 Created objects:"
echo "--------------------------------------"
printf " %-2s %-29s %s\n" "1." "Python sync script" "$PYTHON_FILE"
printf " %-2s %-29s %s\n" "2." "Bash change check script" "$CHECK_FILE"
printf " %-2s %-29s %s\n" "3." "systemd check service" "$SERVICE_FILE"
printf " %-2s %-29s %s\n" "4." "systemd check timer" "$TIMER_FILE"
printf " %-2s %-29s %s\n" "5." "systemd debounce timer" "$DEBOUNCE_FILE"
printf " %-2s %-29s %s\n" "6." "systemd sync service" "$SYNC_SERVICE_FILE"
echo "--------------------------------------"
echo "📂 SOURCE_ROOT (for TubeArchivist): $SOURCE_ROOT"
echo "📂 TARGET_ROOT (for hardlink) : $TARGET_ROOT"
echo "📝 LOG_FILE : ${LOG_FILE%/}/tubearchivist_sync.log"
echo "📈 LOG_LINES : $LOG_MAX_LINES"
echo ""
echo "🧭 Service diagram:
[tubearchivist-check.timer] ──every 5s──▶ [tubearchivist-check.service]
│
│ checks 📂 $SOURCE_ROOT
│ for changes
▼
┌─ if changes detected ──┐
│ │
[tubearchivist-debounce.timer] ──10s──▶ [tubearchivist.service]
│ (delayed start) │
│ │ runs make_readable_names.py
│ │ creates hard links in the
└────────────────────────┘ 📂 $TARGET_ROOT
"
- Сделать файл исполняемым
chmod 700 /home/install.sh - Запустить скрипт
bash /home/install.sh
![]() Как настроить:
Как настроить:
После запуска скрипта в диалоговом режиме будет предложено задать три необязательных параметра:
Enter the directory for hardlinks with readable names (optional, default name: readable). TARGET_ROOT:
Название директории с hardlink-ами (человекочитаемыми именами). Если пропустить эту настройку, то директории будет присвоено значение по умолчанию: readableEnter the path for the log file (optional, default path: /opt/tubearchivist/script/). LOG_FILE:
Путь до директории с лог-файлом. Если пропустить эту настройку, то будет присвоено значение по умолчанию: /opt/tubearchivist/script/Enter the maximum number of lines in the log file (optional, default=100). LOG_MAX_LINES:
Максимальное количество строк в лог-файле. Если пропустить эту настройку, то будет присвоено значение по умолчанию: 100
![]() Какие объекты будут созданы:
Какие объекты будут созданы:
- Python скрипт синхронизации директорий
/opt/tubearchivist/script/make_readable_names.py - Bash скрипт для проверки изменений в исходной директории youtube
/opt/tubearchivist/script/check_changes.sh - systemd таймер запуска сервиса проверки
/etc/systemd/system/tubearchivist-check.service - systemd сервис проверки
/etc/systemd/system/tubearchivist-check.service - systemd таймер задержки запуска сервиса синхронизации
/etc/systemd/system/tubearchivist-debounce.timer - systemd сервис синхронизации
/etc/systemd/system/tubearchivist.service
![]() Пример содержимого лог-файла:
Пример содержимого лог-файла:
22.02.2026 23:15:22 - Scanning Elasticsearch...
22.02.2026 23:15:22 - Creating the channel directory: /mnt/tubearchivist/readable/Kанал Альфа
22.02.2026 23:15:23 - File added: /mnt/tubearchivist/readable/Канал Альфа/Введение в Системы.mp4
22.02.2026 23:15:23 - File added: /mnt/tubearchivist/readable/Канал Альфа/Введение в Системы.ru.vtt
22.02.2026 23:15:23 - File added: /mnt/tubearchivist/readable/Канал Альфа/Настройка Сети.mp4
22.02.2026 23:15:23 - File added: /mnt/tubearchivist/readable/Канал Альфа/Настройка Сети.ru.vtt
22.02.2026 23:15:23 - File added: /mnt/tubearchivist/readable/Канал Бета/Основы Базы Данных.mp4
22.02.2026 23:15:23 - File added: /mnt/tubearchivist/readable/Канал Бета/Основы Базы Данных.ru.vtt
22.02.2026 23:15:23 - File added: /mnt/tubearchivist/readable/Канал Гамма/Установка Виртуальной Машины.mp4
22.02.2026 23:15:23 - File added: /mnt/tubearchivist/readable/Канал Гамма/Установка Виртуальной Машины.ru.vtt
22.02.2026 23:15:23 - Done ✔
![]() Пример отчёта после выполнения скрипта:
Пример отчёта после выполнения скрипта:
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
🎉 SYNCHRONIZATION SETUP COMPLETED
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
📊 Summary:
--------------------------------------
Step 1 - Python check ✅
Step 2 - Script directory ready ✅
Step 3 - Preparing sync script ✅
Step 4 - Configuration variables set ✅
Step 5 - Sync script created ✅
Step 6 - Check script created ✅
Step 7 - Permissions set ✅
Step 8 - Check service created ✅
Step 9 - Check timer created ✅
Step 10 - Debounce timer created ✅
Step 11 - Sync service created ✅
Step 12 - Services activated ✅
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
Total steps executed: 12
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
🆕 Created objects:
--------------------------------------
1. Python sync script /opt/tubearchivist/script/make_readable_names.py
2. Bash change check script /opt/tubearchivist/script/check_changes.sh
3. systemd check service /etc/systemd/system/tubearchivist-check.service
4. systemd check timer /etc/systemd/system/tubearchivist-check.timer
5. systemd debounce timer /etc/systemd/system/tubearchivist-debounce.timer
6. systemd sync service /etc/systemd/system/tubearchivist.service
--------------------------------------
📂 SOURCE_ROOT (for TubeArchivist): /mnt/tubearchivist/youtube
📂 TARGET_ROOT (for hardlink) : /mnt/tubearchivist/readable
📝 LOG_FILE : /opt/tubearchivist/script/tubearchivist_sync.log
📈 LOG_LINES : 100
🧭 Service diagram:
[tubearchivist-check.timer] ──every 5s──▶ [tubearchivist-check.service]
│
│ checks 📂 /mnt/tubearchivist/youtube
│ for changes
▼
┌─ if changes detected ──┐
│ │
[tubearchivist-debounce.timer] ──10s──▶ [tubearchivist.service]
│ (delayed start) │
│ │ runs make_readable_names.py
│ │ creates hard links in the
└────────────────────────┘ 📂 /mnt/tubearchivist/readable
Если у кого есть опыт использования другого аналогичного сервиса, то обязательно делитесь в коментах.